概要
この数年間、パロアルトネットワークスは、.NETファイル分析用のPythonライブラリの内部開発に取り組んできました。現在、このライブラリは安定しており、一般公開して、リサーチコミュニティと共有するのに十分成熟したと判断しました。
本稿はdotnetfileライブラリを紹介します。dotnetfileを利用すると、.NET Portable Executable (PE)ファイルから重要情報を簡単に抽出できます。基本的な解析機能に加えて、dotnetfileによっていくつかの高度な機能も実装されるので、自動と手動の両方の分析タスクが実行しやすくなります。ここでは、このライブラリに含まれているMemberRefハッシュという新しい独自のフィンガープリント技術についても説明します。
すぐに技術的詳細を確認したい場合は、コードおよびドキュメントをご覧ください。
| Unit 42の関連トピック | Malware |
目次
概要
.NETの背景
dotnetfile
フィールドおよび構造解析
ImplMapおよびModuleRef - 非公開のインポートテーブル
高度な機能
MemberRefハッシュ
TypeRefハッシュの再実装
エントリポイントの検出
メタデータ対策
結論
.NETの背景
.NETは、オープン ソース ソフトウェア フレームワークで、主にMicrosoftによって開発されました。.NETは、マネージド ソフトウェア フレームワークです。つまり、コード実行はランタイムコンポーネントによって管理され、CPUは元のコードを直接実行しません。サポートされているほとんどのプログラミング言語が高度ですが、.NETはオペレーティングシステムと直接対話するインターフェイスを提供します。これらすべてのことから、.NETはソフトウェア開発において優れたプラットフォームと言えます。このようなプラットフォームでは合法的利用が多数ですが、マルウェア作成者が優れたソフトウェア開発リソースを利用することも多く、.NETプラットフォームも例外ではありません。
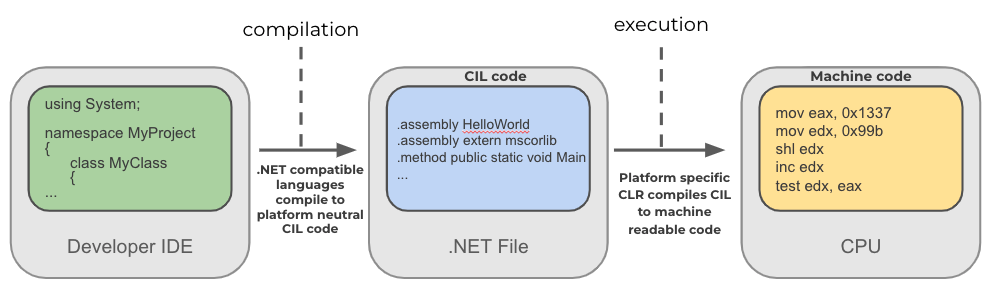
次に示した図は、.NETのコンパイルおよび実行のプロセスを図式化したものです。.NET対応のプログラミング言語は、適切なコンパイラによって、プラットフォーム中立の共通中間言語(CIL)バイトコードにコンパイルされます。CILは基本的には.NETバイナリ命令セットです。実行時に、プラットフォーム固有の共通言語ランタイム(CLR)コンポーネントによって、CILがX86やX64アセンブリなどのネイティブコードにコンパイルされます。CLRは、CILバイトコードをネイティブの命令に変換することに加えて、管理された方法での.NETプログラムの実行、メモリ管理、タイプ検証などさまざまな処理も行います。
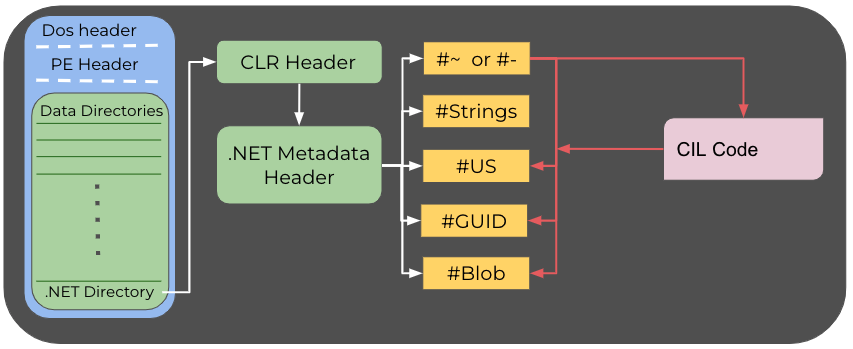
ファイル形式について言えば、一般的な.NET PEファイルは、それに対応するネイティブのPEとは異なります。COR20ディレクトリとも呼ばれる.NETデータディレクトリからすでに異なっています。このディレクトリは、CLRヘッダーを示し、そのCLRヘッダーは.NETメタデータヘッダーを示します。これら2つのヘッダーは実行可能ファイルに関するグローバル情報を保持します。.NETメタデータヘッダーは通常、次の5つのストリームを示します。
- #~または#- – メタデータストリーム。#~は、データが最適化されることを示し、#-はデータが最適化されないことを示します。このストリームには最大56個の異なるメタデータテーブルが含まれます。
- #Strings – このストリームはメンバー名、クラス名、メソッド名などのシステム文字列のヒープです。
- #US – ユーザー文字列リテラルが含まれます。
- #GUID – GUIDを保持します。一部の実行可能ファイルでは、プロジェクトに関連付けられているGUIDがこのストリームに含まれている場合があります。
- #Blob – このストリームには、バイナリ配列などのバイナリオブジェクトが含まれます。また、メソッドのシグネチャがエンコード形式で格納されます。
その他のいずれのストリームも、.NETでは使用できません。別の文字列が存在する場合、それは難読化プログラムや保護プログラムによって、解析ツールを遮断するために「ジャンク」として挿入された可能性があります。
#~に含まれるさまざまなメタデータテーブルは、CILコードでのオフセットを示します。そのようなテーブルの一つが「Method」メタデータです。このテーブルの各エントリが、CILコード内にこのテーブルによって記述されているメソッドの開始オフセットを示します。CILコードは、ストリームに保持されている情報を参照します。たとえば、次の参照は、コードがユーザー文字列ヒープ(#US)から文字列を利用する際に生じます。
ここでは、.NETの簡単な概要のみを提供しています。詳細に関心をお持ちの場合は、ntcoreの記事または公式のCLI仕様をご覧ください。
一般的に言えばこの概要は正確ですが、言及されていないこともあります。この「大まかな」説明では触れていないエッジケースが実際に確認されていることです。
dotnetfile
dotnetfileライブラリは、従来のpefileライブラリにちなんで名付けられました。使用法も非常に似ています。実際、メインオブジェクトDotNetPEはpefileのPEオブジェクトを継承しています。dotnetfileライブラリは純粋なPythonライブラリです。つまり、何もコンパイルする必要がなく、サードパーティの.NET実行可能ファイルに依存する必要もありません。リサーチャーの皆様がファイル分析ワークフローを自動化するときや手動によるサンプル調査をスピードアップするときに、このライブラリが役立つことを願います。
フィールドおよび構造解析
dotnetfileは、.NET PEからほぼあらゆるフィールドと構造を抽出します。次のような解析情報を得ることができます。
- CLRヘッダー。
- .NETメタデータヘッダー。
- #~に含まれるメタデータテーブル。テーブルのエントリはメソッド、クラス、メンバーなどさまざまです。
- システム文字列。
- ユーザー文字列。
- .NETリソース: メタデータおよび未加工のデータのソースが解析されます。リソースは書き込み時にデシリアライズされません。
ImplMapおよびModuleRef: 非公開のインポートテーブル
ほとんどの場合、.NET PEファイルのインポートテーブルには、.NETランタイムライブラリmscoree.dllを参照するエントリのみが格納されます。そのうえ、これらのエントリで、プログラムの機能についてあまり多くが示されることはありません。これは、多くの場合、インポートの同じ非公開のセットがインポートテーブルに存在するためです。
ImplMapメタデータテーブルには、管理対象のコードからアクセスできる管理対象外のメソッドに関する情報が格納され、ModuleRefテーブルには、それぞれのモジュール情報が格納されます。P/Invokeは、この情報に依存します。Windows APIを使用することが想定されているサンプルでは、宣言されたAPIはこれらのテーブルに格納されます。注目すべき点は、Windows APIまたはその他のネイティブコードへのアクセスは、実行時にAPIを解決することによって実現できることです。したがって、このような場合、ImplMapテーブルに必ずしもAPIの情報を格納する必要はありません。
dotnetfileは、管理対象外のメソッドを簡単にリストする方法を提供します。
高度な機能
dotnetfileには、重要な情報を抽出できるようにする基本的な解析機能に加えて開発された機能がいくつか含まれています。これらの機能にはパロアルトネットワークスが作成したロジックとヒューリスティクスが含まれているため、これらの機能のグループを「高度な機能」と呼ぶことにしました。このロジックは、.NET PEファイルについてのパロアルトネットワークス独自の高レベルの見解を伝えるもので、単純な解析機能ではありません。
リサーチャーにはこれらの機能のメリットをさまざまなタスクやアプリケーションで享受してもらえることと思います。
MemberRefハッシュ
MemberRefハッシュは、.NETサンプル専用に開発された革新的な新しいフィンガープリント技術です。他のフィンガープリント技術と同様に、サンプルのグループ化、クラスタ化、および検出に使用できます。
この技術の理解を深めるために、まずはMemberRefメタデータテーブルについて詳しく見ていきましょう。MemberRefテーブルに含まれているものはほとんどが、メソッド、プロパティ、フィールドなどの.NETランタイム構造です。このテーブルは簡単には難読化できないことがわかっています。つまり、このテーブル内の情報は、難読化されたサンプルのグループ化に有用です。
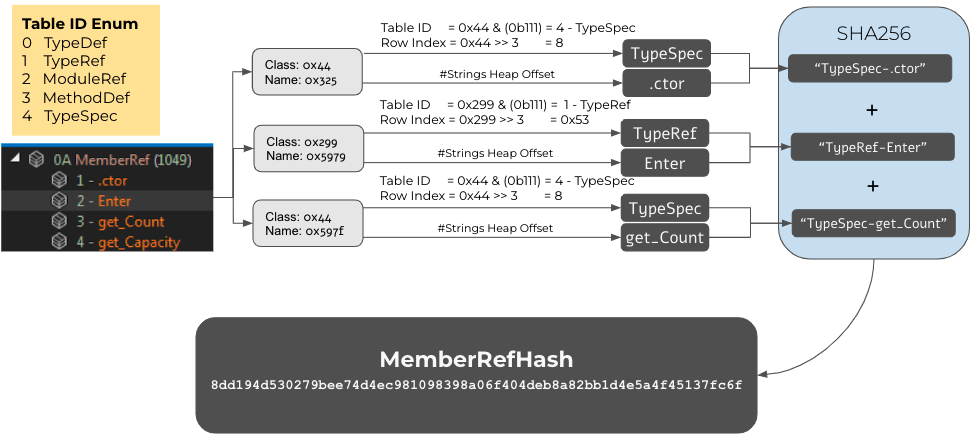
MemberRefハッシュは、次のプロセスに従って、MemberRefテーブルに対して計算されます。
- MemberRefテーブルのエントリごとに、メンバー名を表す文字列が取り出され、NAMEに割り当てられます。
- また、エントリごとに、対応するクラスのテーブル名が取り出され、TABLEに割り当てられます。
[これは、最初はわかりにくいかもしれませんので、さらに詳しく説明します。各エントリには、クラスと呼ばれるフィールドがあり、これは5つのテーブル(TypeDef、TypeRef、ModuleRef、MethodDef、TypeSpec)のいずれかのエンコードされたインデックスです。このエンコーディングは、正式にはMemberRefParentエンコーディングと言います。最下位の3つのビットは、テーブルIDを表し、上位13個のビットはリモートテーブル内のインデックスを表します。MemberRefハッシュアルゴリズムの場合、テーブルIDのテキスト表現がキャプチャされます(TypeSpecなど)。簡素化するために、テーブルIDのみが使用されます。リモートテーブルからの実際の情報を使用する追加ステップは、このアルゴリズムには含まれていません。それらのテーブルそれぞれに固有のデータ構造およびデータタイプがあるためです。また、現在の実装は「厳密」すぎないため、サンプルのグループ化に使用できます。] - テーブルID (TABLE)のテキスト表現とメンバー名(NAME)はTABLE.NAMEとして連結されます。
- ステップ3のエントリはすべてテキストとして連結されます。
- デフォルトで、これらのエントリはMemberRefテーブルでの表示と同じ順序で使用されます。
- エントリを名前でソートするためのフラグを使用できますが、デフォルトでは設定されていません。
- 最終的なMemberRefハッシュは、ステップ4の文字列に対してSHA256を計算した結果です。
次の図は、MemberRefハッシュの計算プロセスを表しています。
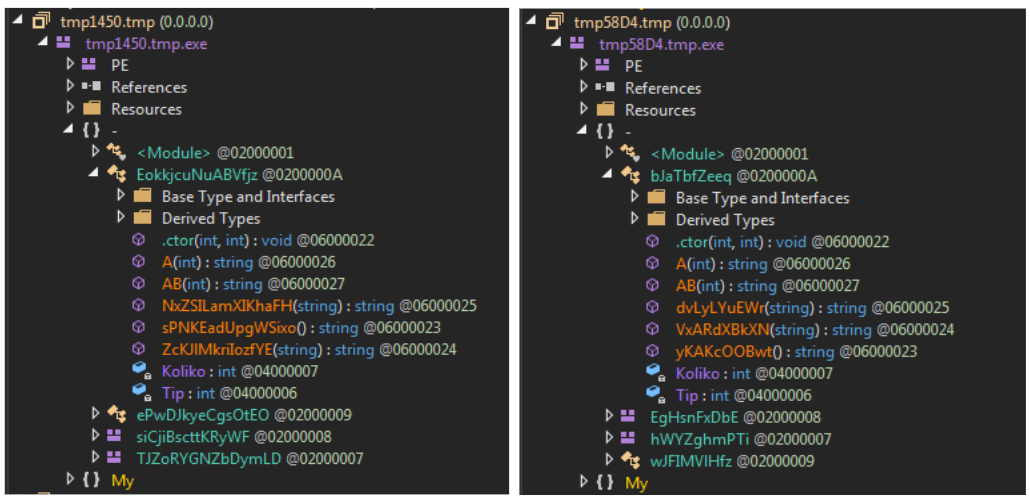
現在も使用されている例を見てみましょう。肉眼では、図4に示された2つのサンプルは非常に似通っているように見えます。しかし、自動化の観点からは、微妙な違いが見えてきます。
ありがたいことに、これら2つのサンプルでは、同じMemberRefハッシュが使用されています。つまり、MemberRefテーブル内のすべてのメンバーの名前とテーブルIDが、両方のサンプルで同じです。また、エントリの表示順も同じです。
TypeRefハッシュの再実装
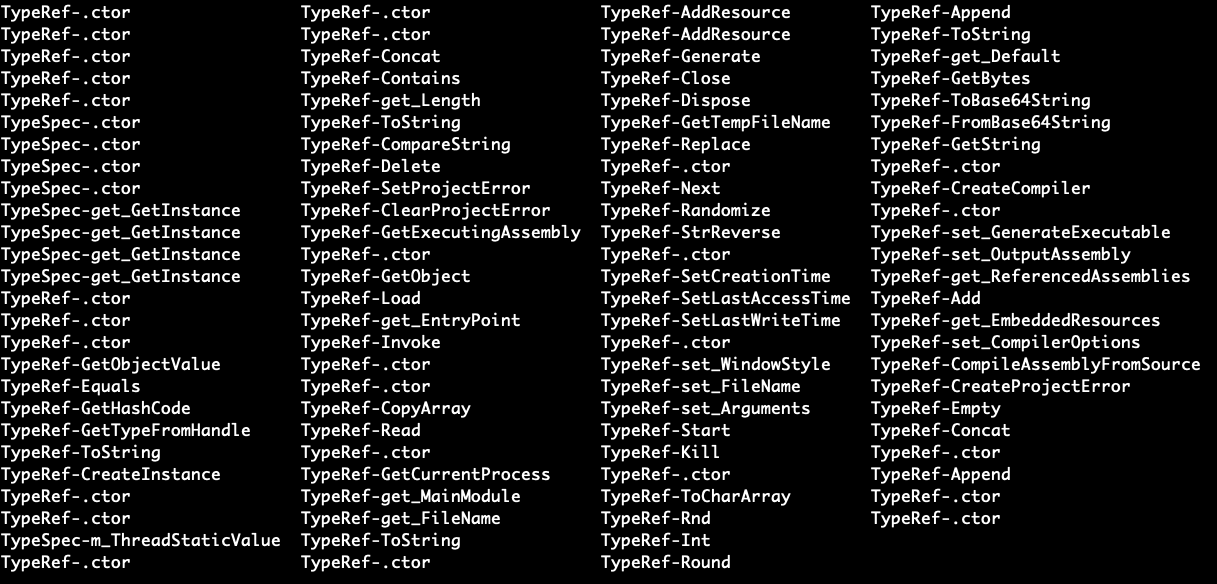
TypeRefハッシュは.NETサンプル向けのフィンガープリント技術で、GDATAによって開発されたものです。参照されるすべての.NETタイプに対してハッシュを計算することが意図されています。TypeRefハッシュは、imphashにある程度似ていますが、主要な違いがいくつかあります。
dotnetfileライブラリには、GDATAの元の実装にいくつかの「ひねり」が加えられたTypeRefハッシュ機能の実装が含まれます。
- 元のTypeRefハッシュ実装では、タイプの名前とタイプの名前空間が使用されます。パロアルトネットワークスのバージョンでは、Namespace名の代わりにResolutionScope名が使用されます。ResolutionScope名は常に存在するからです。
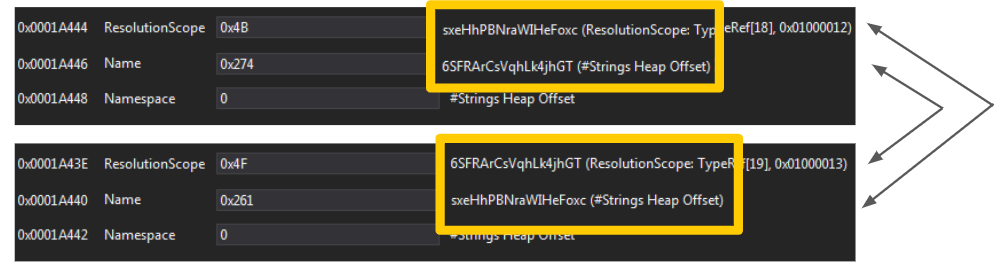
- 一部の.NETパッカーや.NET保護プログラムでは、互いに参照し合うTypeRefメタデータ テーブル タイプが挿入されます。つまり、特定のType AがType Bの下にネストされ、Type BもType Aの下にネストされます。これは明らかに意味をなしていません。このようなテーブルタイプは、解析ツールを遮断するために人為的に挿入された「ごみ」です。別の副次的影響として、これらのタイプの名前は簡単にランダム化できるので(これらの名前は実在しないため)、サンプルごとにTypeRefハッシュが異なるという結果になることが挙げられます。dotnetfileの実装ではそのようなTypeRefエントリをスキップできるため、dotnetfileの実装では、このクラスのサンプルに対してより高い耐性を実現できます。図6は、互いに参照し合うTypeRefエントリの実際の例を示しています。
- 「ごみ」のTypeRefエントリのもう一つのタイプが、存在しないTypeRefエントリを参照するエントリです。図7では、インデックス172のTypeRefエントリを参照するTypeRefエントリと、170個のエントリしかないTypeRefテーブルが示されたサンプルを確認できます。さらに、この例では、NameフィールドとNamespaceフィールドがnullになっています。dotnetfileの実装ではこのようなエントリはスキップされます。

エントリポイントの検出
DllMain関数を常に使用するネイティブのPE DLLとは異なり、.NET DLLではエントリポイントを定義しておく必要がありません。実際のエントリポイントについて理解していないと、.NET DLLを実行しようとしても失敗する可能性が高いです。これらのファイルを動的に分析して、ファイルの特性を完全に明らかにするには、適切なエントリ ポイント メソッドを呼び出す必要があります。
dotnetfileライブラリは、実証済みのヒューリスティクスに基づいて、可能性のあるエントリポイントをリストするためのインターフェイスを提供します。これらのヒューリスティクスは万全ではありませんが、きわめて優れています。
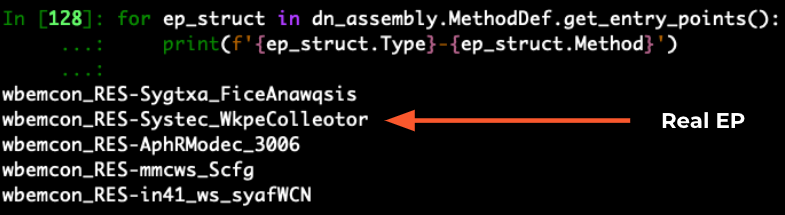
以下の分析ハッシュをご覧ください。可能なエントリポイントが5つだけリストされています。この方法によって、正しいエントリポイントを見つけるための検索空間が大きく絞り込まれます。これら5つのメソッドを手動で調べると、2つ目のメソッドが実際のエントリポイントであることがわかります。
メタデータ対策
パッカーおよび保護プログラムは、多くの場合、さまざまな技術を採用して、解析ツールを遮断しようとします。dotnetfileライブラリには、.NETメタデータ構造におけるこのような異常を特定するロジックが含まれます。このような異常検出メソッドのコレクションをメタデータ対策と呼びます。このライブラリで検出される異常には、次のようなものがあります。
- 偽の.NETストリーム
- ModuleテーブルおよびAssemblyテーブル内の異常な数(複数)のエントリ
- 無効な文字列エントリ。ConfuserExで採用されている場合が多い
- .NETメタデータヘッダー内の余分のバイト。有効だが異常
- 無効なTypeRefエントリ
- PEヘッダーのデータディレクトリ数の改ざんの試み(OPTIONAL_HEADER.NumberOfRvaAndSizes)。これにより、.NETデータディレクトリが効果的に隠される
- 自己参照するTypeRefエントリ。対応する解決スコープの調査で検出される
このロジックはまだテスト段階にありますが、.NET PEサンプル内の異常検出に使用でき、検出アプリケーションの機能として利用できます。


 脅威アクター グループ
脅威アクター グループ





