概要
LockCryptはEncryptServer2018という別名でも知られるランサムウェアファミリで、2017年の半ばからインターネット上に出回りはじめて以降依然として活発です。このマルウェアはリバースエンジニアリングによる完全な分析を Malwarebytes Labsが2018年4月に行っていますが、利用されている自家製の暗号はお粗末なもので、解読は可能と正しく結論づけています。
ただし、Malwarebytesのリサーチャーは本マルウェア用の復号ツールは公開しておらず、ほかにオンライン上で公開済みの復号ツールも確認できませんでした。また、これ以外にあげられている支援は同ラボの新しいブログエントリしかなく、そこでも同ランサムウェアの被害にあった人はMichael Gillespie (@demonslay335)に復号について相談するよう勧めているのみでした。
そこで私たちはGillepsie氏に連絡を取り、@hasherezade、@FraMauronzの両氏と復号ツールの作成をしましたが、この復号ツールは完全とはいえませんでした。既知の平文ファイル(1MB)が大量に必要でしたし、復元できないファイル名があったり、ファイルの末尾1-2バイト分が復号できずに残る場合があったのです。
これを受け、本稿では、本マルウェアの自家製暗号について分析した結果とその解読方法、また25KB程度のごく小さい平文のみで暗号キーを復元する方法について説明します。このシナリオであれば現実的といえるでしょう。というのも、LockCryptは手当たり次第すべてのファイルを暗号化しますが、DLL のようなアプリケーションファイルもその例外ではないため、同じバージョンのソフトウェアを別のコンピュータにインストールすれば容易に復元可能だからです。復元用スクリプトや手順などは本稿の末尾に記載します。
ただし最近、別の暗号方式を利用する新しい亜種が見つかっている点はご注意ください。私たちはこの新しいバージョンの解析は行っていませんが、こちらはずっと堅牢な暗号が利用されているようです。
初期の分析
このマルウェアの暗号を逆アセンブルしてみてわかったことは、このマルウェアの作成者は、ファイルを暗号化するにあたり、カスタムメイドの非常に弱い暗号を選んだということでした。私たちは、2018年にもなってカスタムメイドの暗号モデルを利用したランサムウェアと遭遇することがあるなどとは思ってもいませんでした。というのも、Windows API を利用すれば、今現在ないし近い将来に利用可能なハードウェアでは復号に数十億年かかるような方式で、簡単にデータを暗号化できるからです(たとえば、十分に暗号強度の高いメソッドを使って生成されたキーを持つ128ビットAES暗号方式など)。
以下に示すのは、本マルウェアの暗号関数を逆アセンブルした結果を同等のPythonコードで示したものです。なお当該encrypt()関数のC言語版はMalwarebyteによる分析に掲載されています。ポインタ操作がある分、こちらの方が分かりやすいかもしれません。
この関数からは以下の結論が導き出せます:
- フェーズ1が定義する変換は周期的で、1サイクルの長さは12500バイト
- フェーズ2が定義する変換は周期的で、1サイクルの長さは25000バイト
- エッジケース(後述)を除き、各平文ビットは3つのキービットとXOR演算される(2つのキーはフェーズ1、残り1つはフェーズ2で)
- つまり、フェーズ2で行われたビット シフトを「取り消す」(バイト順を入れ替え戻した上で5ビット分ROR演算を行う)ことで、両フェーズをひとまとめとし、長さ25000バイトの周期的キーをもつストリーム暗号として扱うことができる(また、それがオリジナルのキーの機能でもある)。
最後の2つの結論について次の図で説明します。この図はデータの4バイト目から8バイト目を変換する様子を、各暗号関数のそれぞれのステップの流れを追って可視化したものです。各行の間にある⊕という記号は、それらのビットが互いにXOR演算されているということを意味しています。
変換が行われる前の4バイト目から8バイト目の各ビットは以下のような状態です:
![]()
フェーズ1ループの2回目の繰り返しが終わった後は次のようになります:

フェーズ1ループの3回目の繰り返しが終わった後は次のようになります:

フェーズ1ループの4回目の繰り返しが終わった後は次のようになります(フェーズ1のループはすべて同じことの繰り返し):
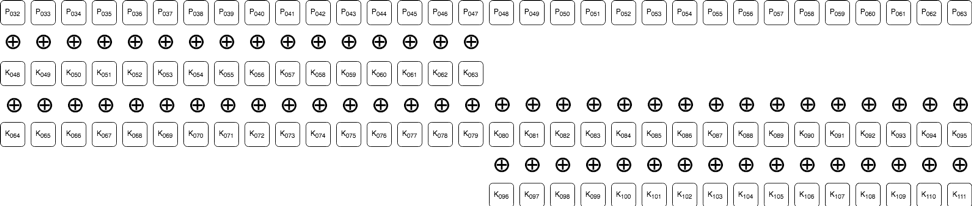
フェーズ2ループの2回目の繰り返し中、ROL演算が終わった後は次のようになります:

フェーズ2ループの2回目の繰り返し中、XOR演算が終わった後は次のようになります:

バイト順を入れ替えてこれらのバイトの暗号化は終了です。
「ストリーム キー」を復元する
先の図で暗号化された4バイト目から8バイト目を使い、バイト順の入れ替えを元に戻して5ビット分ROR演算をすると次の結果が得られます:
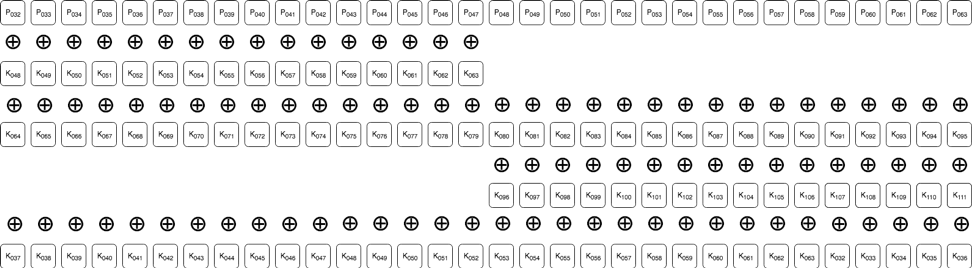
要するに、この演算(バイト順の入れ替えを元に戻して5ビット分ROR演算する)により、この暗号を典型的なストリーム暗号に「正規化」したわけです。この後、これらのバイトと既知の平文とのXOR演算を行えば、先の結論4で述べたキー ビットの機能が得られます:
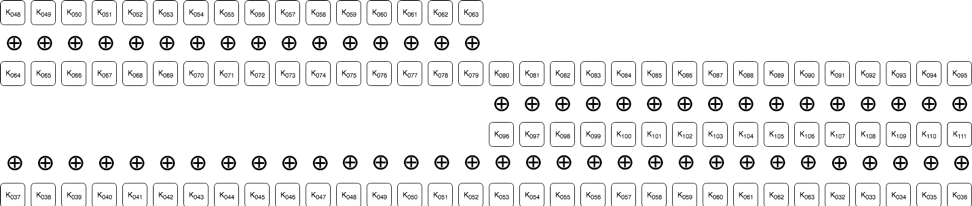
このストリーム(実際には各ビットがキー ビットと3回XOR演算されている)を「ストリーム キー」と呼ぶことにしましょう。このストリームキーは25000バイト長のサイクルで周期性があるので、25000(25k)バイトの長さの平文と暗号文があれば、キーを復元してファイルを復号するのに十分といえそうです。
なにか既知の平文と暗号データのペアを次のPythonの関数で処理すればストリーム キーを復元できます。ここでインデックス パラメータは、与えられた文字列中の25000バイト分の既知の平文バイトに対するインデックスを示しています。ただし、先頭4バイト分は暗号化されることがないため、ここから 4 を引いています。つまり、平文の文字列のインデックスidx+4からidx+4+25000の範囲が使用されます。このため、既知の平文ファイルのサイズが50000バイトなら0 <= idx < 24998の範囲が利用されます。
それではいよいよ(まだ不完全ですが)次の関数を使ってファイルを復号していきましょう:
残念ながら、上記のソリューションにはいくつかのエッジケースは扱えていません:
- 暗号化された最初の2バイト(元のファイルの4バイト目から6バイト目)は、2つのキー ビットとしかXOR演算されていないので:
- 残りのバイトを復号するには、idx >= 2 のストリーム キーを使う必要がある
- 最初の2バイトを復号するには、idx == 0 のストリーム キーを使う必要がある
- 元ファイルのサイズが2 (mod 4)に等しくなければ、encrypt()関数にlen(plain) != 0 (mod 4)があることから、ファイルの末尾1-2バイトはフェーズ1の最終の繰り返し回によってしか暗号化されていないことになる。これら末尾1-2バイトの各平文ビットは1つのキービット(得られていないキー ビット)としかXOR演算が行われていないため、復号できない。
さらにMalwarebytesが示したように、ファイル名はオリジナルのキーのサブセットと直接XOR演算して暗号化されているため、ファイル名も復号できません。ただし、@demonslay335 氏が復号ツールの中で使っているように、暗号化されたファイル名の長さをmとした場合、n >= m の長さをもつ既知のファイル名があれば復号は可能です。
つまるところ、任意の長さのファイルとファイル名を復元したければ、本稿で述べたストリーム キーだけでなく、実際のオリジナル暗号キーが必要そうだ、ということです。
オリジナル暗号キーを復元する
実は、これまでの分析から(XORを加算演算とするガロア体(2)上の)連立一次方程式が得られ、ストリーム キーとオリジナル キーをこの方程式で結びつけることができるようになります。この分析を一般化するなら、次のPythonの関数によって、オリジナル キーをそのビット インデックス間でXOR演算した結果が得られ、それが各ストリーム キーのビット(i をインデックスとして使用)が生成されます:
つまり、stream_key[i] == reduce(xor, (key[k] for k in k_for_i(i))) ということです。
この関数により、ガロア体(2)上に、オリジナル キーとストリーム キー間の変換を表す200000x200000の非常に疎な行列が生成されます:
この行列Aは、A_i_j_s[i]列だけが1で、残りの行iはすべて0となります。
またこの行列は各行に3つしか値がないという「非常に」疎な行列なので、普通のコンピュータ上で線形代数モデルを使って解くことも可能です。たとえば数学ソフトウェアのSageMathで次のコードを実行させます:
検証してみたところ 16GB の RAM を搭載した Intel Core i7-4790 CPU と SageMath 上でこの方程式を数十分から数百分程度で解くことができました。重要なファイルを完全に復元したいなら、これは十分実用的といえるでしょう。なお、idxが25000の倍数であれば、処理が速くなるようです。これは、行列が行階段形に近くなるためかもしれません。したがって、十分に大きい(50KB以上など)既知の平文ファイルがあるならidx = 25000とすることを推奨します。
ファイルを復号する
以上をまとめますと、マルウェアが利用する暗号キーを復元する手順は以下のようになります:
- 暗号化済ファイルについて、暗号化される前の平文ファイルを用意します。この元ファイルは、少なくとも 25006 バイト以上のものが必要です。
- 暗号化前の元ファイルを用意するには、ランサムウェアによって暗号化されたソフトウェアと同じバージョンのソフトウェアを別のコンピュータ上にインストールしてから、ファイルサイズをヒントとして、暗号化された DLL ファイルと対応する平文DLLファイルを探すとよいでしょう。
- まだインストールされていない場合はPython 2.7をインストールします。
- recover_stream_key.pyスクリプトを使い、暗号化されたファイルとそうでないファイルのペアから特定のidx用のストリーム キーを復元します。
- 先に説明したとおり、十分に大きな平文ファイルがあるならidx = 25000にすることをお勧めします。
- SageMathをインストールします。
- SageMath Jupyter Notebookを開き、「オリジナル暗号キーを復元する」セクションに記載されている 3 つのコード スニペットを上から順にペーストしてから実行します(訳注: 日本語版ではコード部分を画像として記載しておりますので、ここでは英語ブログの「Recovering the original key」セクションからコピーすることをおすすめします)。これによりオリジナルの暗号キーを復元します。
- 重要: コード実行前に必ずスニペット上部に記載されている3つのパラメータをご自身のものに書き換えてください。
- 検証によれば、この段階に20分から数時間かかることがあります。
- 本稿末尾のリンクからダウンロードしたdecryptor.pyスクリプトで、暗号化されたファイルを復号します。
本稿の分析とスクリプトファイルが、当該ランサムウェアの被害に遭われた方々の失われたファイルを復元するお役に立てば幸いです。
両スクリプトはこちら のUnit 42チームのGitHubからダウンロードできます。



 主なサイバー脅威
主なサイバー脅威

 脅威アクター グループ
脅威アクター グループ


