概要
本稿では、「高度なWildFire」に組み込まれたハイパーバイザーベース サンドボックスからメモリーベースのアーティファクト(痕跡)を取得し、これらのアーティファクトを中心にして作成された機械学習パイプラインについて、Unit 42のリサーチャーが解説します。この代替アプローチは、さまざまな回避技術を使うマルウェアへの検出精度を高めるために考案されました。
本シリーズのほかの記事でも解説していますが、マルウェアの作者は、静的解析やサンドボックスといった戦略を無効化するため日々欺瞞術を研鑽しています。パッキングやサンドボックス回避など、技術の開発と変化はたゆみなくつづいており、まさにモグラたたきの様相です。どの検出チームもこれに追いつくのに苦労しています。
さらに悪いことに、構造解析や静的シグネチャ、さまざまな動的解析をはじめとする一般的な検出技術は、広く蔓延するマルウェアファミリーで日々観測されるような、増大する一方の複雑性にうまく対抗しきれていません。
| 関連するUnit 42のトピック | Sandbox, evasive malware, machine learning, AI, memory detection |
静的装甲と回避術で完全防備
難読化、パッキング、プロセスメモリーに動的にインジェクトしたシェルコードの実行など、マルウェアの作者が回避技術を採用するケースが増えつづけています。ファイル構造を手掛かりにするマルウェア検出はいつもうまくいくとは限りません。パッキング技術でファイル構造をじゅうぶん修正すれば、これらの手がかりは排除されてしまうのです。このため、このクラスの特徴量だけを学習した機械学習モデルでは、こうした回避技術を使うサンプルをうまく検出できません。
また、この検出方法に代わるものとして、サンドボックス内でのマルウェア実行の痕跡から悪質性を予測する機械学習モデルを利用する方法も一般的です。ですがこのシリーズの前回の投稿でも詳しく説明したとおり、サンドボックス回避はごく一般的に行われていますので、サンプルがエミュレート環境にいることをうかがわせる数々の手がかりを察知するや、ペイロードが実行をやめてしまうこともめずらしくありません。
またマルウェアは不注意あるいは意図的にサンドボックス環境を破壊したり、ログファイルを上書きしたり、低レベルのトリックを使ったりと、いくらでも解析妨害の要因をつくることができます。つまり実行ログから機械学習モデルを学習させるだけではこうした回避型マルウェアは捕捉できません。
NSIS Crypterで暗号化されたGuLoader
本稿では、Nullsoft Scriptable Install System (NSIS) Crypterで暗号化したGuLoaderダウンローダーの1つを分析していきます。NSISは、Windowsインストーラーを作成するオープン ソース システムです。
| ハッシュ | cc6860e4ee37795693ac0ffe0516a63b9e29afe9af0bd859796f8ebaac5b6a8c |
静的解析が役に立たない理由
GuLoaderマルウェアは暗号化され、NSISインストーラー ファイルで配信されます。このNSISインストーラー ファイルはファイルの内容を最初にアンパックする必要があるため、静的解析には向いていません。アンパックしても、そこにあるのは暗号化されたデータとNSISスクリプト1つだけです。このスクリプトそれ自体にもコードを動的に復号する部分があって、それも検出を難しくする要因の1つとなっています。
しかも、これがマルウェアかどうかを識別する構造上の手がかりもあまりありません。したがってPortable Executable (PE)ファイルの構造にもとづいて学習させた機械学習モデルは、このファイルをほかの良性ファイルとうまく区別できません。
NSISスクリプトとGuLoaderシェルコードの抽出
NSISスクリプトをアンパックするには古いバージョンの7-Zip (バージョン15.05)が必要です。このバージョンの7-Zipはスクリプトをアンパックできますが、これより新しいバージョンはNSISスクリプトのアンパック機能が削除されています。ファイルの中身とNSISスクリプト(図1)をアンパックしたら、スクリプトの解析に着手し、GuLoaderのサンプルがどのように動くのかを確認できます。
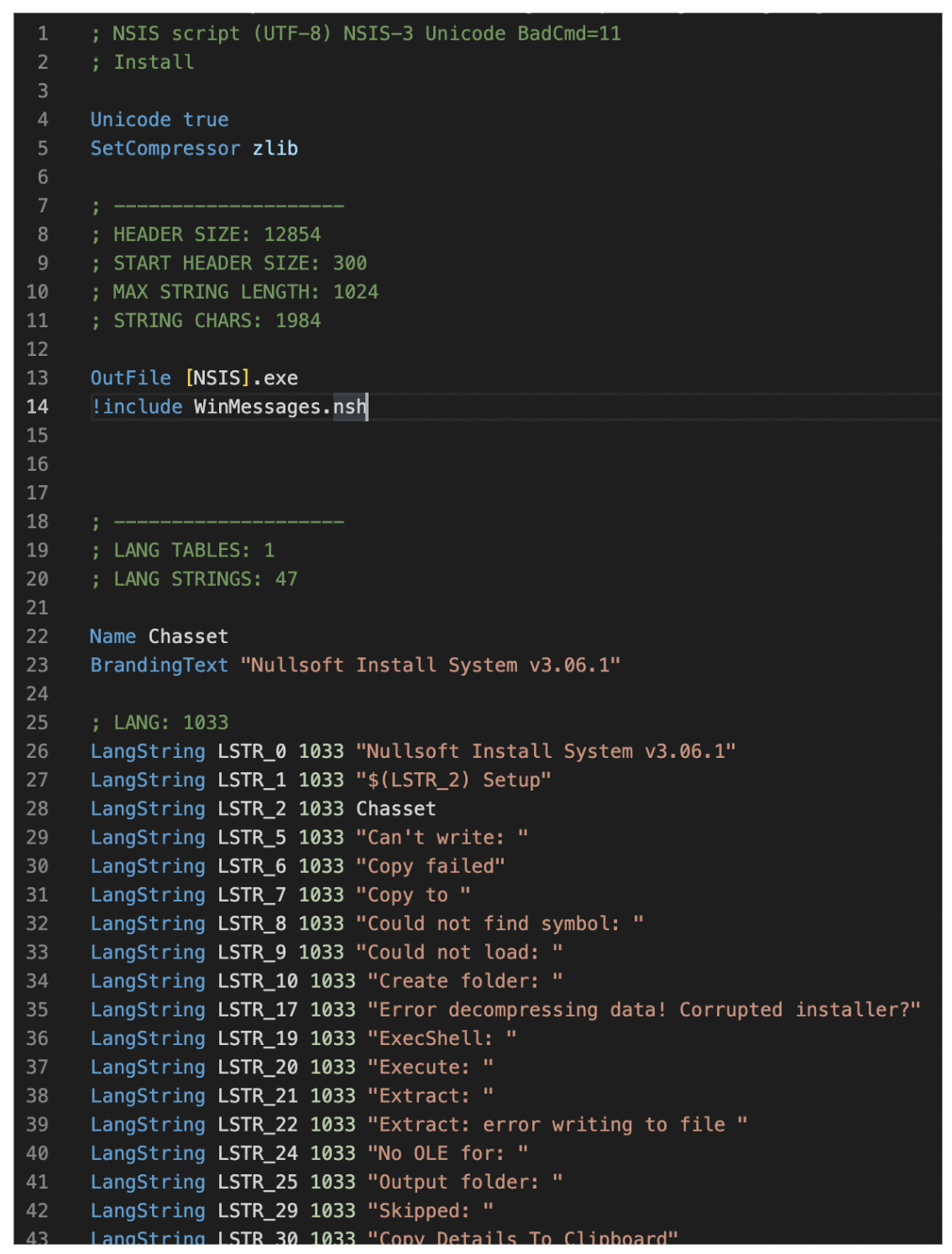
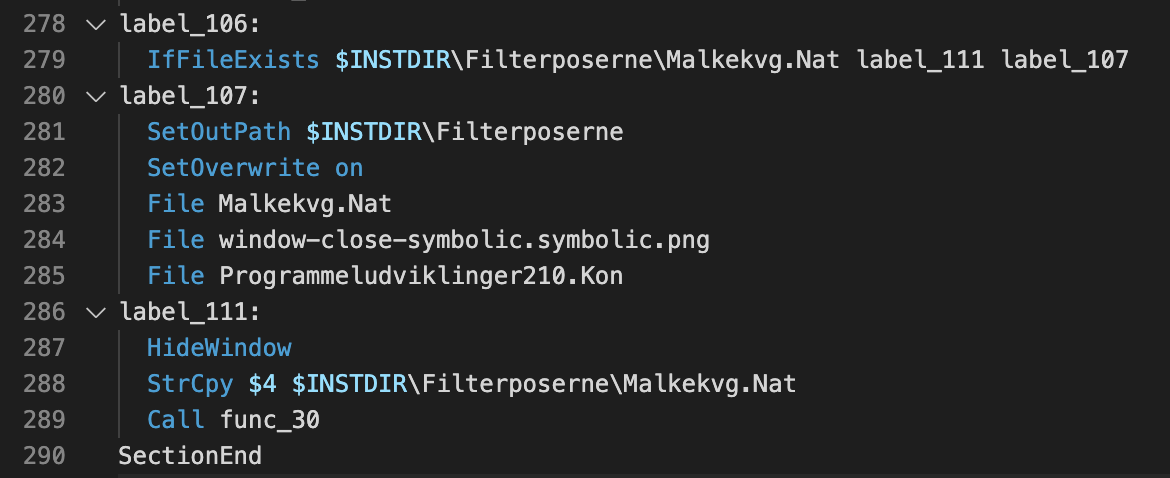
スクリプトを下にスクロールしていくと%APPDATA%\Farvelade\Skaermfeltetという名前のフォルダが新たに作成され、ここにファイルがコピーされていることに気づきます。理由は不明ですがここで使用されているファイルパスはデンマーク語のようです。このコピー動作の後のスクリプトは通常のインストールロジックですが、ここにfunc_30という興味深い関数があります。
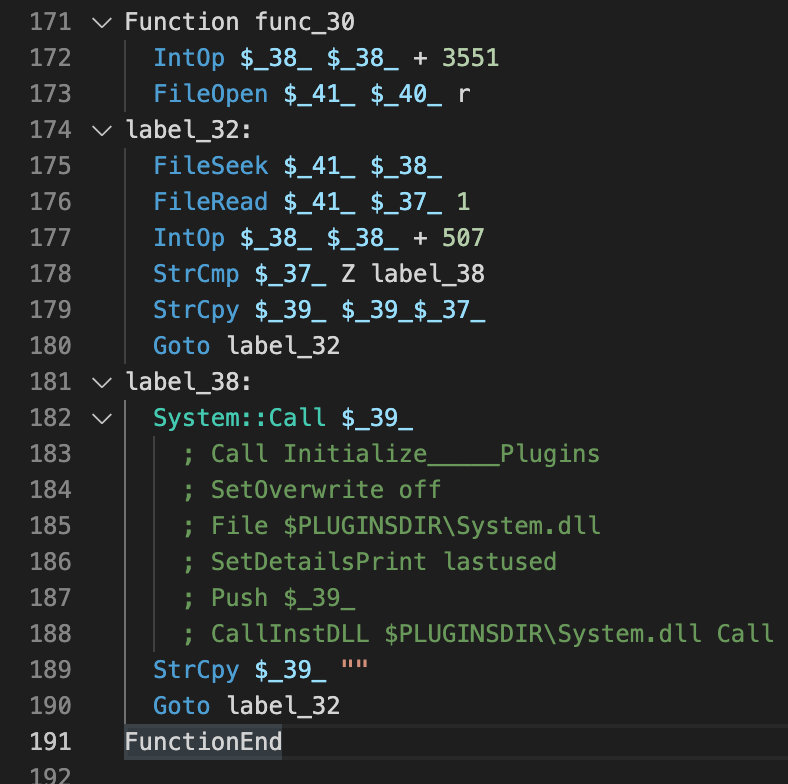
この関数を呼び出す前に、$INSTDIR\Filterposerne\Malkekvg.Natという文字列が$4という文字列変数にコピーされます(図2と図3)。この関数func_30は、Programmeludviklinger210.Konファイルからデータを読み込んでコードを組み立てます。そしてZという文字が確認された直後に、組み立てたコードを呼び出します。
開発者はNSISを使ってWindows DLLからエクスポートした任意の関数を呼び出せます。またその結果をNSISのレジスタ/スタックに直接保存できます。この機能によってマルウェアの作者は実行時にWindows API関数を動的に呼び出せます。つまり、解析前の評価が必要な静的解析は難しくなります。
動的なコードをデコードするため、短いPythonスクリプトを書き、このなかで動きを再現してWindows APIコールを抽出します。
図4は上記スクリプトを実行した結果をデコードしたデータです。

デコードされた関数群が一緒になってNSISアーカイブのべつのファイルからシェルコードを読み込み、EnumWindows関数で実行します。この処理を疑似コードで書くと次のようになります。
残りを解析しやすいよう、シェルコードを持ったPEを1つ生成することにします。実行ファイルを生成するにはCerbero ProfilerのようなツールやLIEFのようなPythonライブラリを使います。
今回はLIEFライブラリを使って新しい実行ファイルをビルドしました。あとはファイルMalkekvg.Natの内容を持つ新しいセクションを追加して正しいオフセットになるようにエントリーポイントを設定するだけです。これがすめばIDA Proでシェルコードを開き(図5)、有効なx86命令を含んでいることを確認できるはずです。
シェルコードの解析
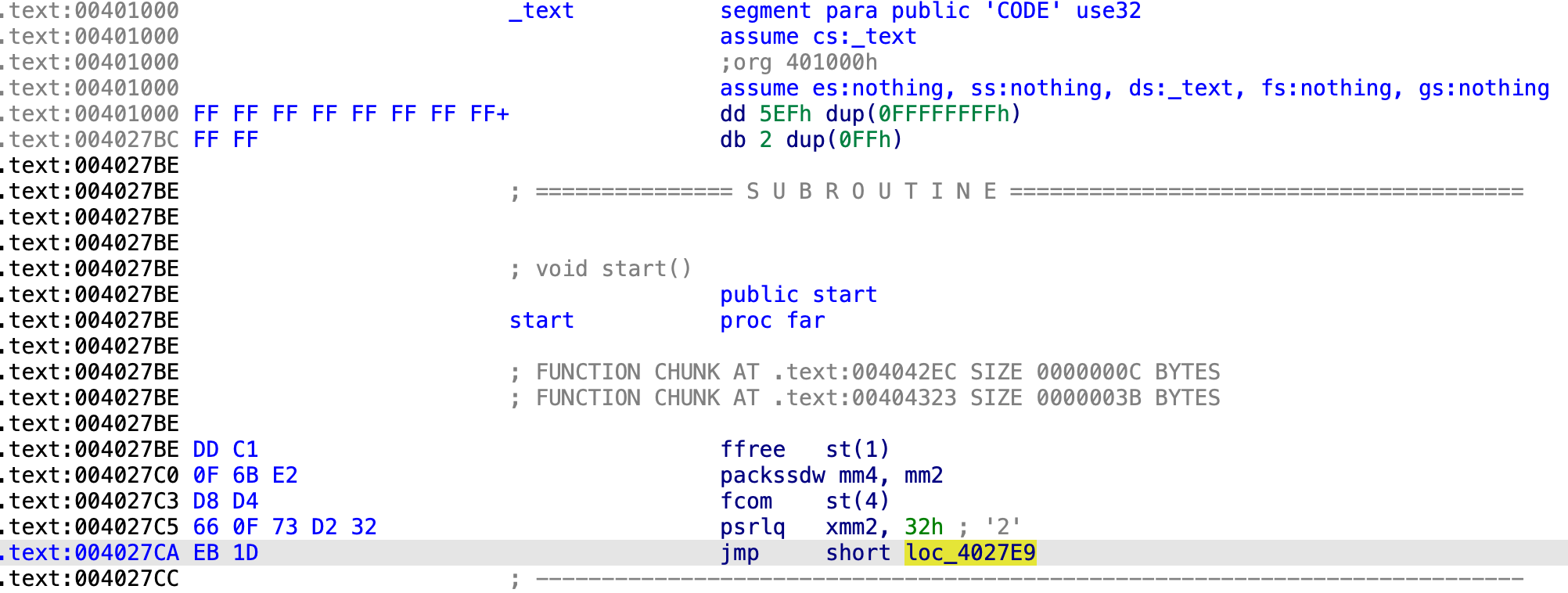
これでPEファイル内にシェルコードの第1ステージができたので、動的解析で実行して何が起こるかを見てみます。最初にわかることは、これが仮想マシンを検出するとメッセージボックスを表示して実行を停止することです。このテキストは実行時に4バイトのXORキーで復号されます。
![]() IDA Proでファイルを開いてコードを少したどると、第1ステージ復号用の大きな関数が目に入ります。Graph Overviewで見るとこの関数は大きく見えますが、ジャンクコードの特定は容易です。
IDA Proでファイルを開いてコードを少したどると、第1ステージ復号用の大きな関数が目に入ります。Graph Overviewで見るとこの関数は大きく見えますが、ジャンクコードの特定は容易です。
復号を担うコードは下の図7で確認できます。図8からは第2ステージにジャンプする最後の呼び出しを確認できます。この時点で、第2ステージをべつの実行ファイルにダンプして復号できます。
メモリーから直接実行ファイルをダンプしてもよいですが、エントリーポイントが正しいアドレス(この例では0x404328)を指すよう、パッチを当てる必要があります。


第2ステージには解析対策技術がたくさん使われていますが、ここで説明すると長くなるしほかでも解説されているので、詳しい説明は省き、いくつか紹介するにとどめます。
- 既知のサンドボックスを示す文字列がないかメモリーをスキャン
- ハイパーバイザーのチェック
- 時間の計測
- インストラクション ハンマリング
GuLoaderがダウンロードする最終ペイロードの取得には、これらのチェックすべてを手動で回避するか、これらの技術に耐性のあるサンドボックスで実行するか、ベアメタル サンドボックスで実行するかのいずれかが必要です。
ペイロード情報の抽出
第2ステージを解析せずにペイロード情報(すべての文字列を含む)を取得するには、Spamhausが解説していたちょっとしたワザを使うと便利です。GuLoaderはペイロードURLを含む文字列の暗号化には単純なXOR暗号を使います。
あと必要なのは全部を復号する暗号鍵だけで、うまいことにこの暗号鍵は第2ステージのどこかにあります。
第2ステージ内に存在することがあらかじめ分かっているパターンをなにか1つブルートフォースで調べれば、その文字列を復号できます。それをXOR演算した結果が暗号鍵となります。その場合の制約は、ペイロードのURLをすべて復号できるようにパターンサイズをじゅうぶんに大きくとることだけです。たとえばUser-Agent文字列などがよいパターンでしょう。User-Agentには、たとえばGeckoのように、デフォルトで「Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; rv:11.0)」といった文字列が設定されています。
復号キーを自動ですばやく見つけるには、まずなにか短いパターン(たとえば、User-Agent文字列の最初の8バイト)を暗号化し、その結果がファイルのどこかにあるかどうかを探さねばなりません。それがファイルのどこかにあれば、続けて残りのパターンも暗号化して完全な暗号鍵を得られます。
本稿末尾に上記の方法でペイロードから暗号鍵を見つけるPythonスクリプトを添付しておきました。ダンプされた第2ステージのGuLoaderペイロードにスクリプトを実行すると文字列をいくつかとペイロードのURLを確認できるはずです。
GuLoaderはペイロードURLの前に7〜8文字のランダムな文字を含むことがあり、実行時にこれをhttp://かhttps://に置き換えます。httpかhttpsかの区別はそのランダムなパターンから4番目の文字で行います。
このサンプルの場合、ペイロードURLはhttp://ozd[.]com[.]ar/wp-includes/nHMoYlbGLWls101.qxdで、本稿執筆時点ではこのペイロードはまだオンラインでした。
ダウンロードされた最終ペイロードはFormBookマルウェアファミリーのもので、SHA256値はfa0b6404535c2b3953e2b571608729d15fb78435949037f13f05d1f5c1758173でした。
機械学習でこれを検出する方法
以前べつのブログで、サンドボックスでのライブ実行中にメモリーから抽出できる観測可能なアーティファクトの種類についていくつか詳しく解説しました。そのなかで、複数の回避技術を持つマルウェアの検出には、メモリー解析データを機械学習と組み合せれば非常に強力になることがわかりました。
以下のセクションでは、実行時にメモリー内で何が変更されたかに関するこれらの観測結果をすべて取り込み、この観測結果を大規模な機械学習と組み合わせてマルウェアを検出する戦略を説明します。このアルゴリズムはパターンを自動識別し、マルウェアがメモリー内で痕跡を隠そうとしたり、シェルコードを動的に割り当てて実行したり、アンパッキングを使ったりした場合に示される共通点を識別できます。
このGuLoaderのサンプルの場合、人間の分析者であればすぐに、ユニークな関数ポインターが複数あることを見分けられます。このほか、マルウェアが自身のプロセスメモリー内の複数のページのパーミッションを書き込み可能や実行可能に変更していることにも気づくでしょう。私たちの機械学習モデルは、さまざまなメモリーのアーティファクトから抽出した特徴量を使ってこうした活動を自動で行い、GuLoaderサンプルを検出できます。
本稿のシリーズで以前に説明したように、私たちが高度なWildFireのために作成した自動分析プラットフォームは、これらのメモリーベースのアーティファクトをすべて効率よく自動抽出します。つまり、動的に解決される関数ポインター、パーミッションの変更、アンパックされた実行ファイルに関するすべての情報は、手動で精査した検出ロジックや機械学習パイプラインに追加して利用できます。
機械学習による検出
図9は、前述のメモリーベースのアーティファクトから抽出したカスタム特徴量を学習させた機械学習モデルパイプラインを、私たちがどのように作成したのかをハイレベルで見た図です。私たちが選んだ特徴量は、冗長なアーティファクトのなかから、もっとも役に立つ情報を保持するように作られています。
また、追加情報源としてマルウェアの実行トレースを含め、悪意のあるサンプルを検出するアンサンブルモデルを構築しました。以下の図9に示すように、4つのメモリー アーティファクトとマルウェアの実行トレースからさまざまなカスタム特徴量を自動抽出し、それらを悪意のあるサンプルを検出する分類モデルに渡します。さらにメモリー アーティファクトと実行トレースにもとづく特徴量で学習させるアンサンブルモデルを構築して性能を向上させました。
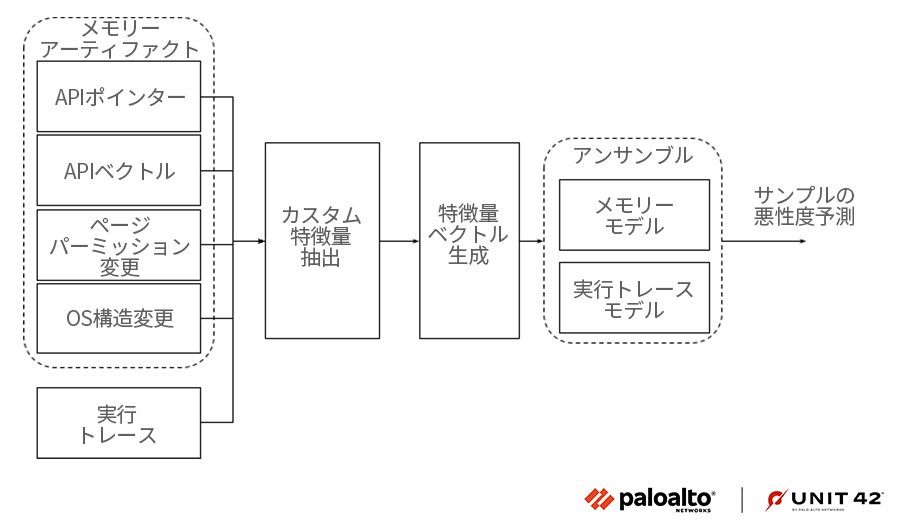
特徴量エンジニアリング
モデルの精度を高めるため、さまざまな特徴量のソースから得た生の値とカスタム特徴量とを比較し、有効性についての実験をしました。ドメイン知識から構築したカスタム特徴量を使うことで、ノイズを減らして全体の特徴量の数を最小化し、「次元の呪い」を回避できます。
同時に、生の値を特徴量に使うことで、攻撃戦術・技術を変化させていくであろう新たなマルウェア トレンドにもすばやく対応できます。私たちは、深層学習を使ってメモリーベースのアーティファクトの関係するログから特徴量を抽出し、これをカスタム特徴量と組み合わせました。私たちの実験ではこの2つのアプローチを組み合わせるとモデルはもっともうまく機能することがわかりました。
モデル選択
モデルの選択では考慮すべき要件がいくつかあります。
- 処理対象のサンプル数が増え続けても機械学習サービスをスケールさせられるように、モデルサイズが小さいこと。
- エラーの発生時は、特定の特徴量ソース(例えば実行トレース)が存在しないことを説明できること。
- 混乱を招く偽陽性が発生した場合、原因となった特徴量を特定できるようにモデルの予測が解釈可能であること。
- モデルが学習サンプルから可能な限り多くの情報保持を試みること。
ドメイン固有の特徴量と、生のデータから抽出したカスタム特徴量で学習させた勾配ブースティング ツリー モデルは、前述の基準の多くを満たしています。
機械学習モデルの学習
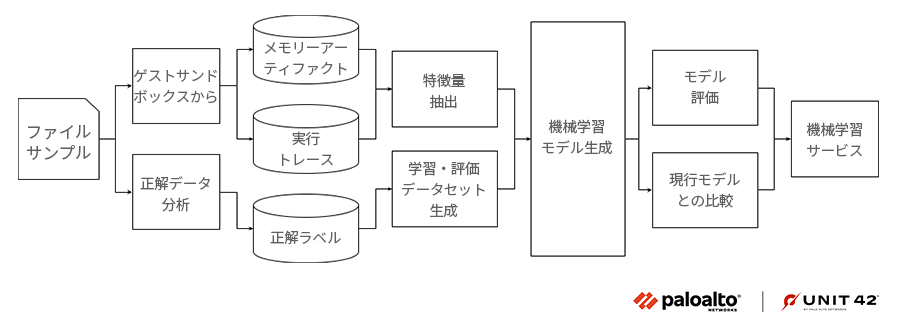
ファイル サンプルはストリーミング パイプラインで処理され、メモリー アーティファクトなどのマルウェアの属性を特徴量ストアに保存します。特徴量の抽出ステージでは、ストリーミングとバッチ処理のPySparkジョブを組み合わせ、モデルの学習で使う最終的な特徴量ベクトルを生成します。
グラウンドトゥルース(正解データ)ラベルは、マルウェアの特徴や研究者の入力にもとづいてサンプルをラベリングする別のパイプラインから得ます。このパイプラインはサンプルの初認日時やハッシュを使って、重複なしの学習データセットと評価データセットを生成します。
機械学習モデルの学習が終了して、事前定義された評価チェック(現在アクティブなモデルに対する期待改善度など)を満たすと、プロダクション環境の機械学習サービスにプッシュされます。
モデル予測の解釈
機械学習モデルの限界と能力を見極めるには、機械学習モデルの予測値を理解することが極めて重要です。機械学習は、学習データの質と種類に大きく依存しますし、予測対象のファイルの状況変化を汎化する能力にも依存しているので、誤検出が起こりやすいのです。ですから、予測のためには、要因となった特徴量を識別する能力が非常に役立ちます。
このプロセスを支えるため、私たちは2つの方法論を用いました。
シャープレイ値の解釈
SHAP (Shapley Additive Explanations)は、あらゆる機械学習モデルの出力の説明に使われているゲーム理論的なアプローチです。SHAP値は、ベースライン予測とは対照的に、ある入力特徴量ベクターについて、各特徴量が実際の予測にどのように貢献したかを説明するものです。図11では、右から左に向かって赤で表した特徴量が、そのモデルを「悪意がある」という予測に向かわせる最上位の特徴量を表しています。左から右に向かって青で表した特徴量は予測が「マルウェアである(悪意がある)」という確率を下げる上位の特徴量を示しています。
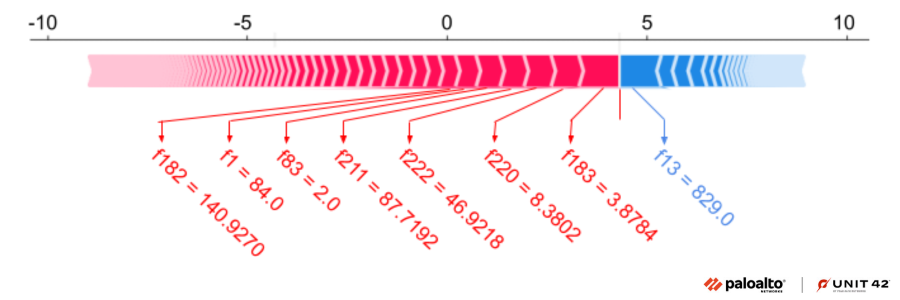
上の図は、SHAP値の大きい上位7つの特徴量と、それに対応する生の特徴量値のForce Plotをプロットしたものです。これら7つの特徴量が存在したことから、私たちの機械学習モデルはGuLoaderを検出できました。これらの特徴量は、動的に解決された複数のAPIポインターとそのメモリー上の相対位置、サンプルが行ったメモリーページのパーミッション変更の相対的な種類に対応するものです。
クラスタリングによる類似サンプルの発見
モデルの予測値を理解するもう1つのアプローチは、学習データセットから類似サンプルを特定することです。私たちはクラスタリング手法として、外れ値や形状の異なるクラスターも許容するDBSCAN (Density-based Spatial Clustering of Applications with Noise)を用いました(図12)。
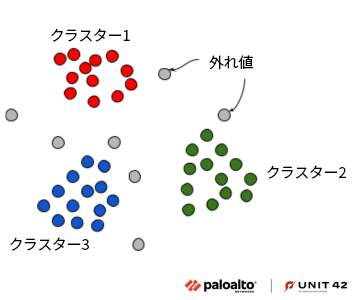
このアプローチはモデルの解釈以外に、同じマルウェアファミリーやAPT攻撃グループに属する類似サンプルを見つける用途でも使えます。DBSCANを使うとGuLoaderのサンプルが存在するクラスターを見つけ出してサンプルを抽出できます。さらに、特徴量空間から類似サンプルを抽出することもできます。
結論
GuLoaderファミリーはサンドボックス回避や静的装甲を利用しています。従来の防御のように、構造的な手がかりや実行ログからだけでは検出が難しいことから、機械学習モデルで検出するマルウェアのサンプルとしてうってつけです。
高度なWildFireには、ハイパーバイザーベースのサンドボックスが導入されています。このサンドボックスは、実行中のGuLoaderのメモリーをひそかに観測し、意味のあるメモリー常駐型のアーティファクトや機械学習検出パイプラインに役立つ情報を解析できます。これにより、観測されたメモリーベース アーティファクトから抽出した特徴量を用いて、悪質な挙動を正確に検出できます。
パロアルトネットワークス製品をご利用中のお客様は本稿で取り上げた脅威から高度なWildFireによって保護されています。








