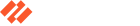
概要
従来のフィッシング検知システムの多くは、WebページのHTML内にログインフォームが存在するかどうかで、ページがフィッシングであるかどうかを判断していました。クライアントサイドクローキングは、フィッシング検知システムを回避するために攻撃者が使用する一般的技術で、Webページのフィッシングコンテンツを見せる前に複雑なユーザー操作を要求したり、ユーザーのブラウザでページがレンダリングされてからJavaScriptを使用してページにフィッシングコンテンツを注入したりします。
これらの回避技術に対抗するため、HTMLページのscriptタグ内に含まれるJavaScriptコンテンツに基づいてフィッシングWebページを検出するよう、ある深層学習モデルに学習をさせました。「PhishingJS」と名付けられたこのモデルはパロアルトネットワークスのクラウドサービスである「Advanced URL Filtering」内で稼働していて、多くの既存フィッシング検出システムでは検出できないJavaScriptベースの高度な攻撃用フィッシングURLを、現在は週に15,000件、追加で検出しています。
パロアルトネットワークスのお客様で、Next-Generation FirewallとAdvanced URL Filteringのセキュリティサブスクリプションをお持ちの方は、本稿で説明する高度なフィッシング攻撃から保護されています。
クライアントサイドクローキング
既存のフィッシング検知システムの多くは、WebページのHTML内にログインフォームやブランドロゴなどの指標が存在するかどうかで、そのページがフィッシングページであるかどうかを判断しています。
こうしたフィッシング検知システムを回避するためにサイバー犯罪者がよく使うようになってきた回避テクニックがクライアントサイドクローキングです。攻撃者はJavaScriptを使ってクライアント側でフィッシングコンテンツ(検知システムでよく検出されるのと同じタイプのコンテンツ)を動的にレンダリングすることが増えています。まずはユーザーに操作を求め、その後でないと認証情報窃取の兆候を示さない場合もあります。ページがレンダリングされた後になってようやくHTML文書内にフィッシングコンテンツが表示されることから、これらのフィッシングページを従来のフィッシング検出エンジンで捕捉することは難しくなっています。
図1-2では、クライアントサイドクローキングのテクニックを用いたフィッシングWebページの例を示しています。このページでは、ユーザーのApple IDアカウントで異常な活動が見られたので、その活動に関連した返金手続きが必要であると主張しています。
Webページにアクセスしても、すぐに目につくようなフィッシングフォームはありません。ユーザーが「Confirm Refund Request (返金リクエストの確認)」ボタンをクリックすると、そこではじめて認証情報窃取用のフォームが表示されます。クローラーベースのフィッシング検出システムの大半は、この手の操作に対応しておらず、この種のフィッシングページは検出をすり抜けることがが多くなっています。
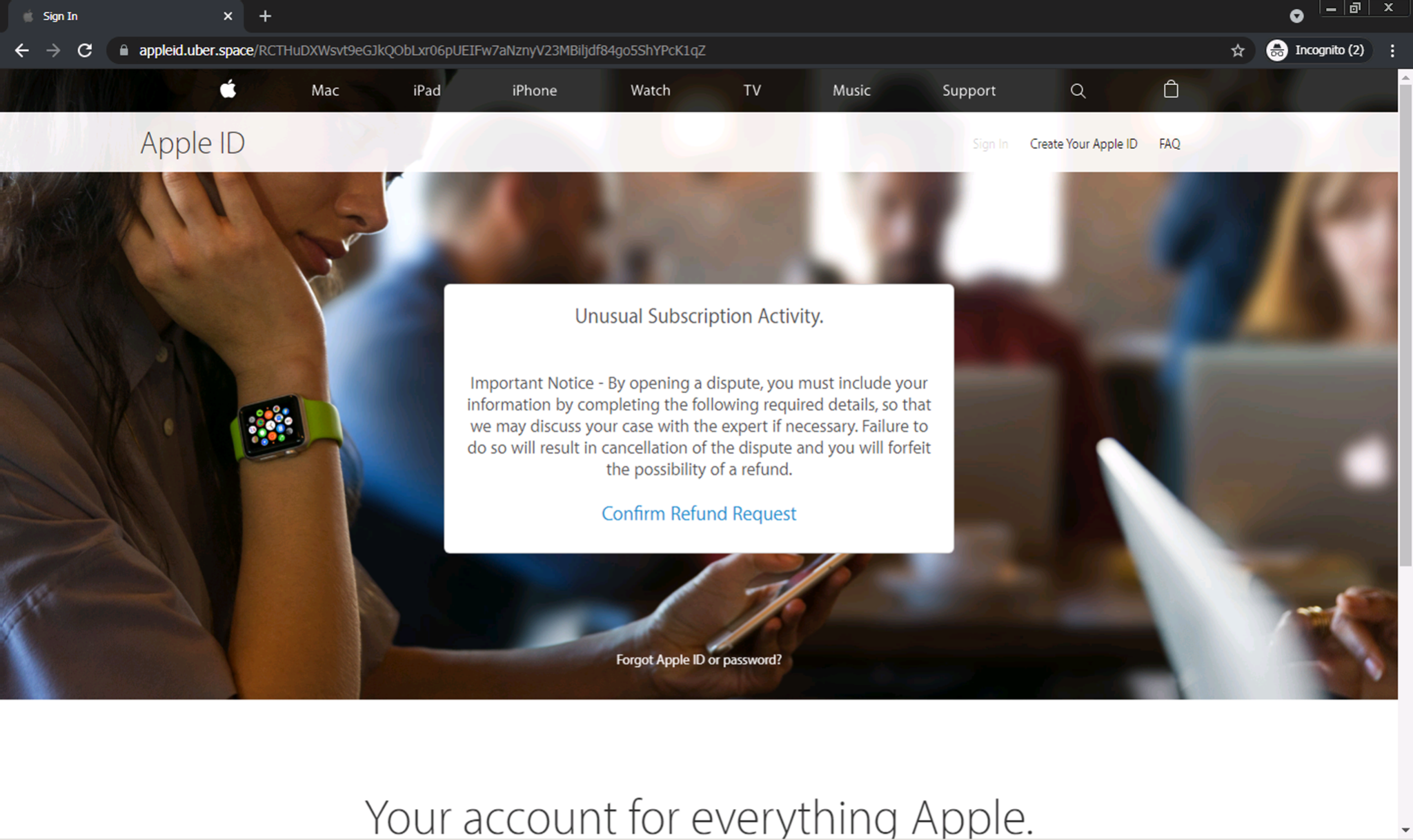
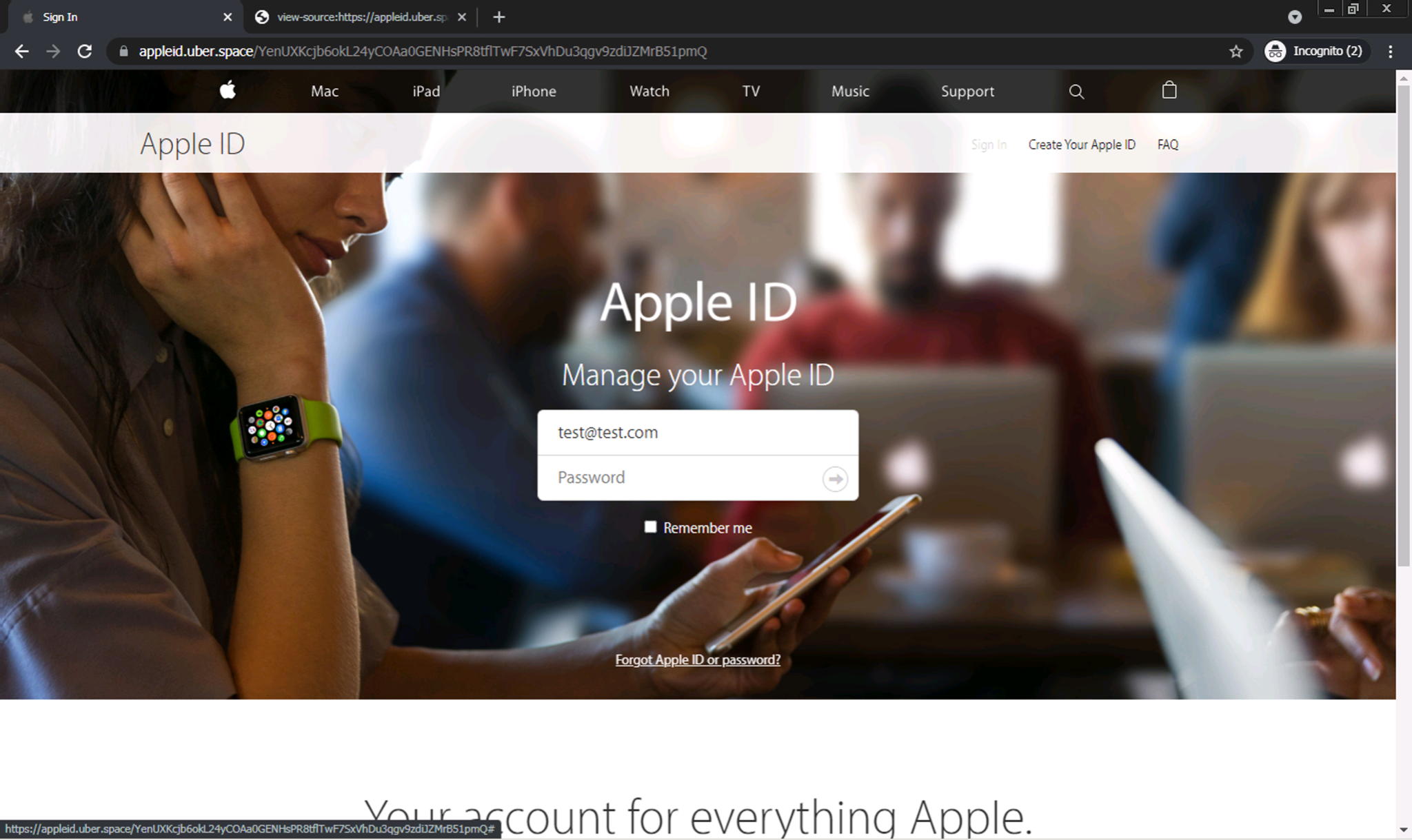
このページのソースコードを調査したところ、ページのコンテンツのほとんどがHTML本文には直接存在しないことがわかりました。かわりにHTMLソースの一番下に大きなscriptタグがあり、document.write(...)APIを使用してページコンテンツの大部分をHTMLドキュメントに注入していました。この注入は、ページがブラウザでレンダリングされた後で発生します。
さらにこのスクリプトは高度に難読化されていました。これはフィッシング検知エンジンを回避するためと思われます。難読化されたコードはAESの復号を経てdocument.write(...)呼び出しに渡されます。
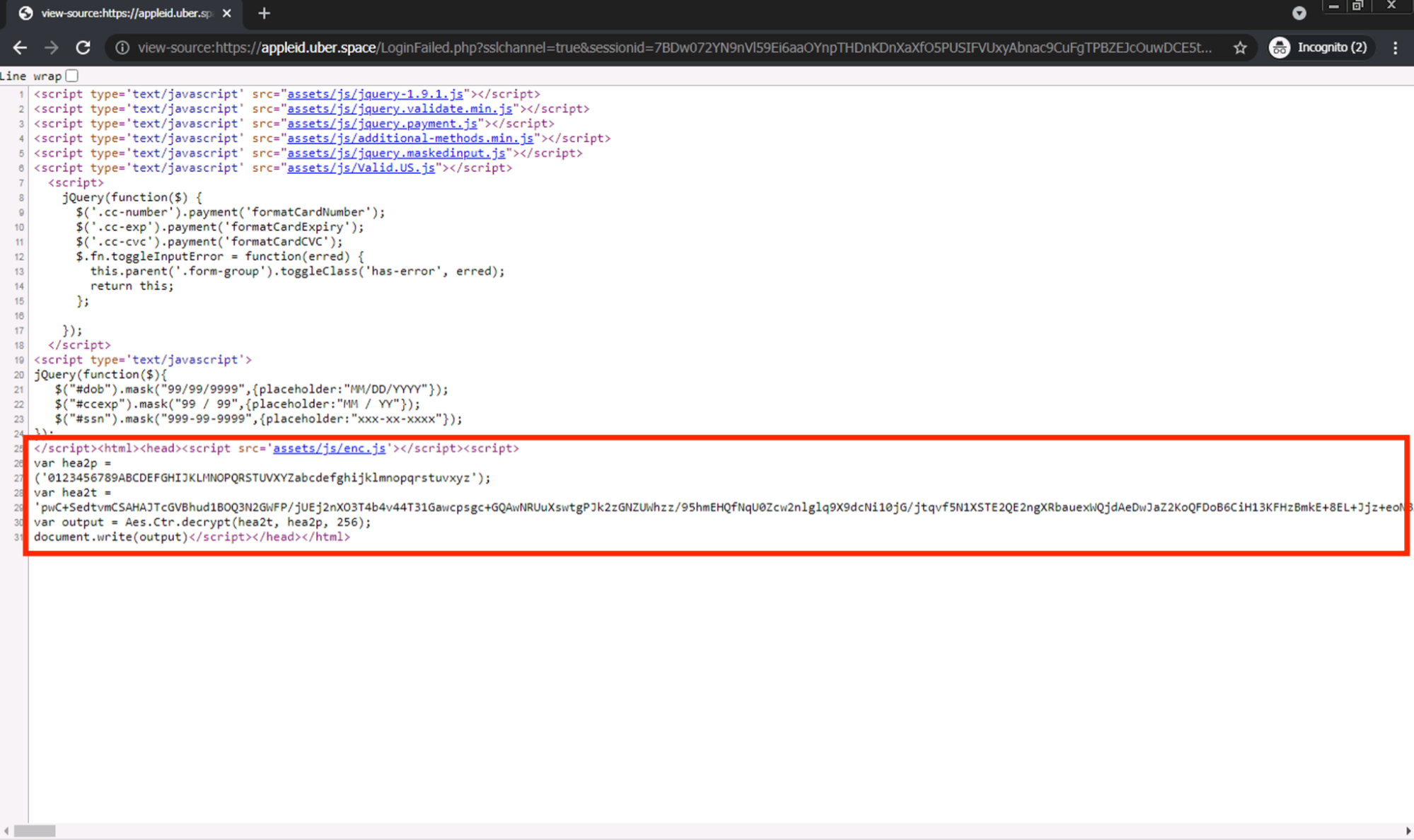
このような洗練されたフィッシングページは従来のフィッシング検出エンジンでは問題となりかねません。そこで、こうしたページをフィッシングに分類するための追加の機械学習(ML)技術を調査しなければなりません。
JavaScriptベースフィッシング用の検出モデル学習方法
私たちはまず学習データ収集用パイプラインをつくり、最近のフィッシングURLからフィッシングJavaScriptのサンプルを継続的に収集しました。サンプル収集はサードパーティのソースで発見されたフィッシングURLに弊社のフィッシング検知システムからのものを加えて行いました。
十分な数のサンプルが集まったところで、約12万件のフィッシングサンプルと、約30万件の良性JavaScriptサンプルを対象に深層学習モデルに学習をさせ、本番環境への移行前にステージング環境でモデルを検証しました。
従来のML(機械学習)の場合、モデルがフィッシングか良性かの活動指標として使用する特徴セットの設計はその道の専門家の手に委ねられていました。これに対して弊社の深層学習モデルは、データセットを繰り返し使って「JavaScriptコードのどのようなパターンがフィッシング(またはその他の疑わしい)振る舞いを示すのか」を学習します。このMLベースのパターンマッチングにより、弊社のモデルは純粋なシグネチャベースの検知技術よりも柔軟性が高いものになっています。また、リサーチャーがこれまであまり目にしたことがない新しく知名度の低いJavaScriptベースのフィッシング手口に対してもより堅牢なモデルになっています。
各scriptタグについて、私たちのモデルは0〜1の範囲でスコアを生成します。ここで1は「スクリプトがある種のフィッシング行為に関連していること」を高い確度で示し、0は「スクリプトが良性であること」を高い確度で示します。たとえば、高度に難読化されたJavaScriptコードや、認証情報窃取フォームをページに注入するコードは、このモデルで高いフィッシングスコアを出力する要因となります。良性のJavaScriptコードは、警告フラグを立てることなくモデルを通過します。
モデルからフィッシングスコアが得られると、様々な閾値を適用し、与えられたURLをフィッシングとしてパブリッシュするかどうかの最終的な判定を下します。PhishingJSモデルは、毎週およそ15,000件の新しいフィッシング検出に貢献しています。つまり、パロアルトネットワークスのお客様(とくにAdvanced URL Filteringサブスクリプションに加入されているお客様)は、実際すでにもこうした洗練されたフィッシング攻撃から保護されていることになります。
PhishingJSの実例
では、私たちのモデルが生成した検出サンプルを紹介しましょう。
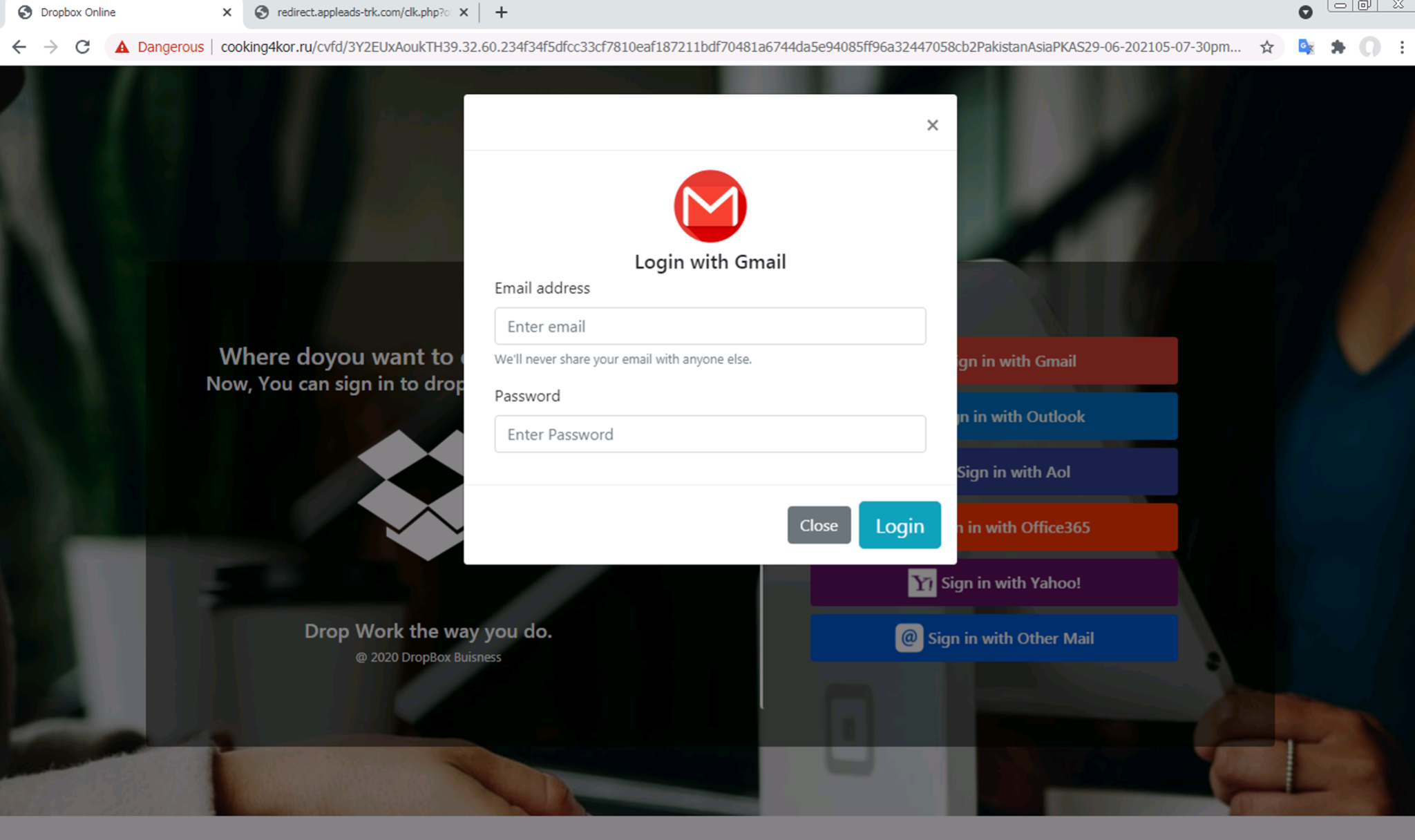
この例で、このモデルがクライアントサイドクローキングを使ったフィッシングページを検出可能であることがわかります。たとえば、ページがユーザーにボタンをクリックさせてから実際の認証情報窃取用フォームを表示するケースです。図4-5は、Dropboxのログインページを装ったフィッシングWebページの例を示しています。ユーザーはまず「Sign in with Gmail(Gmailでサインイン)」または「Sign in with Outlook(Outlookでサインイン)」ボタンをクリックします。その後で、ログイン情報を求めるモーダル画面が表示されます。この特定のURLはスコア0.99998でフィッシングと検出されました。これはモデルが非常に高い確度でこのページをフィッシングとマークしたことを意味しています。

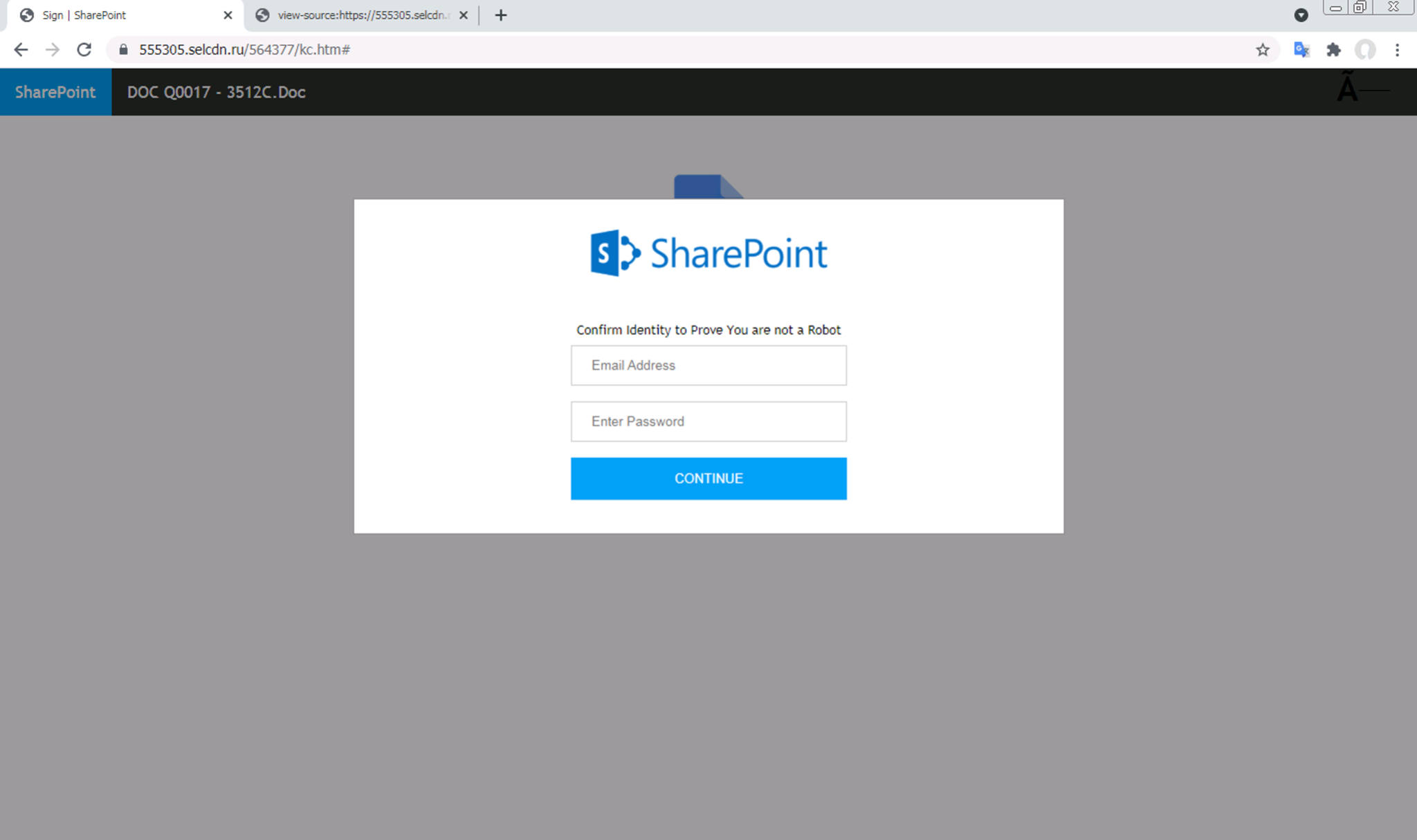
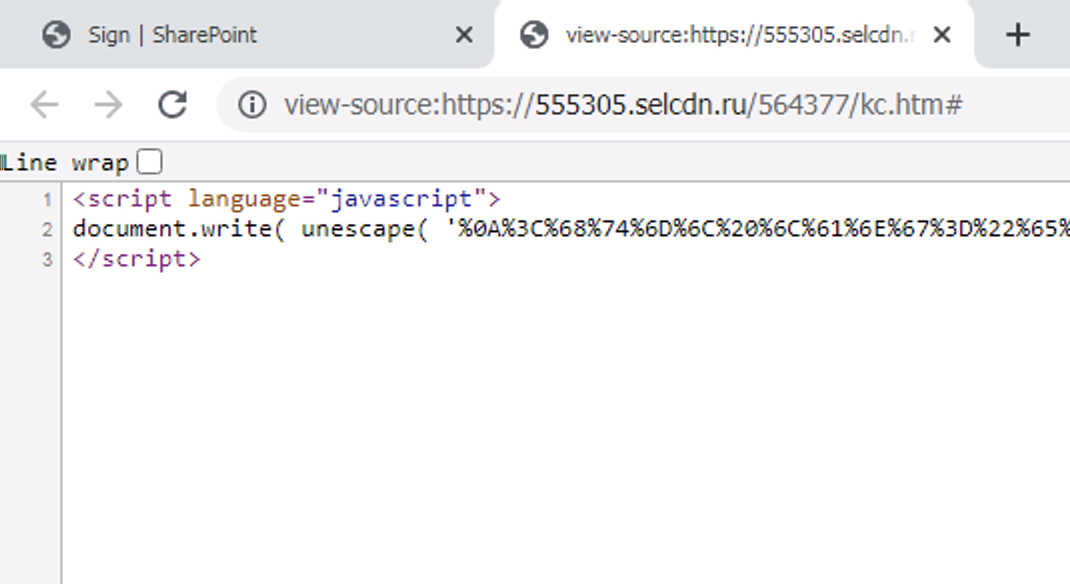
次に、このモデルがフィッシングWebページを生成する高度に難読化されたJavaScriptコードも検出できることを示します。図6はSharePointのログインサイトを装ったフィッシングWebページです。一見、比較的単純なフィッシングページに見えるかもしれません。しかしこのページのソースコードを見るとページ全体が1つのJavaScriptのscriptタグで生成されていることがわかります。図3の例と同様、このJavaScriptスニペットも、高度に難読化された文字列を受け取って解読した後、document.write(...)を呼び出して出力をWebページに注入しています。
このページのHTMLには、すぐにそれとわかる本文や入力フォームがないので、従来型フィッシング検出エンジンの大半を回避してしまう可能性があります。しかし、JavaScriptスニペット自体を分析することで、PhishingJSモデルはこのモデルをスコア
1.00000の高い確度でフィッシングとして検出しました。
このモデルはインタラクティブ性の高い詐欺ページも検出できることがわかりました。図8-10は、Samsung Galaxy S2が無料で当たったという詐欺ページです。ユーザーは、このページを5つのグループまたは20人の友人とWhatsAppで共有するだけで、賞品を受け取ることができるとしています。
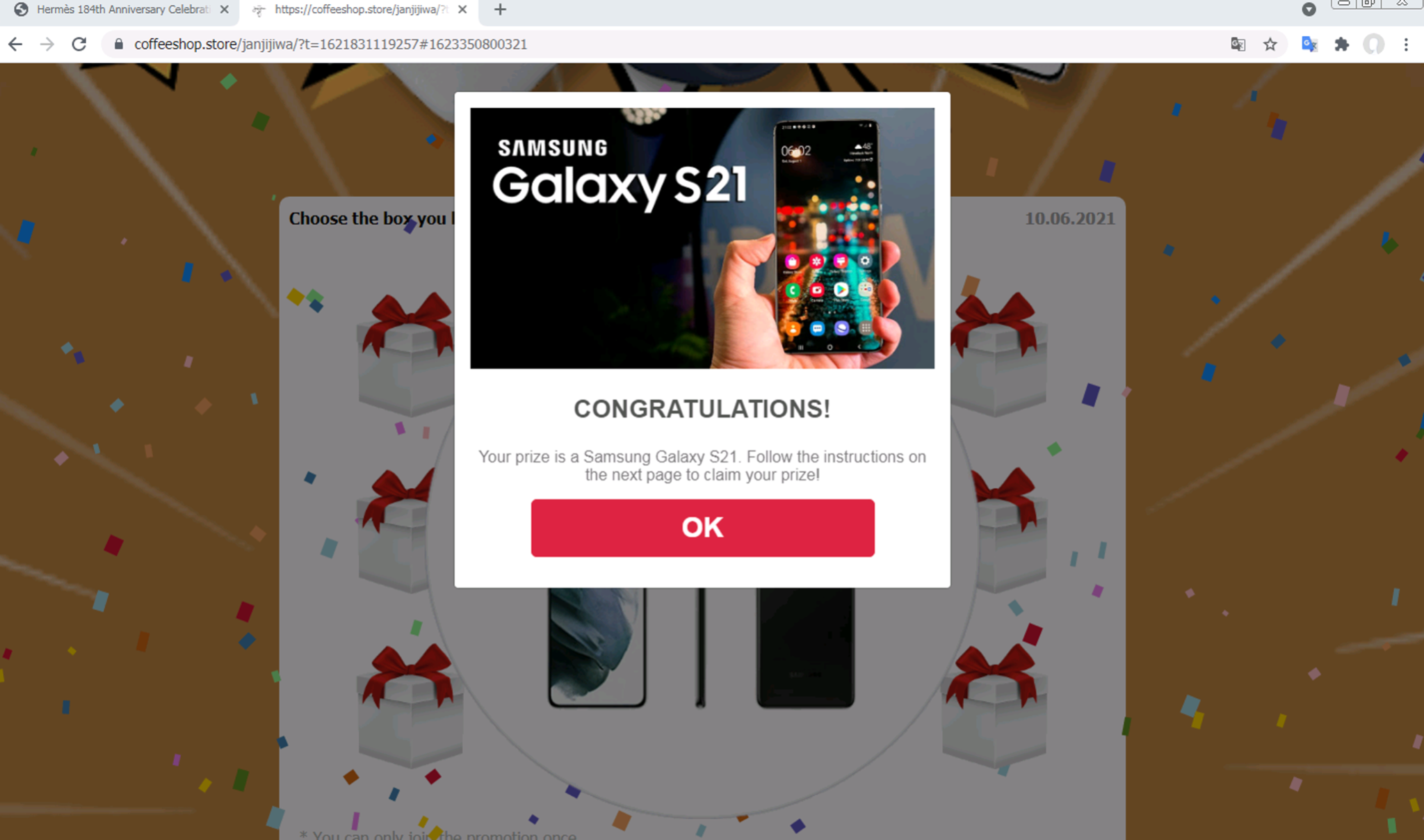
ユーザーが「共有」ボタンをクリックするたびに、ページはユーザーのWhatsAppアプリを開き、別のWhatsApp番号でページを共有するように求めてきます。ページが「共有」されるたびに、青いバーが右に向かって伸びていきます。
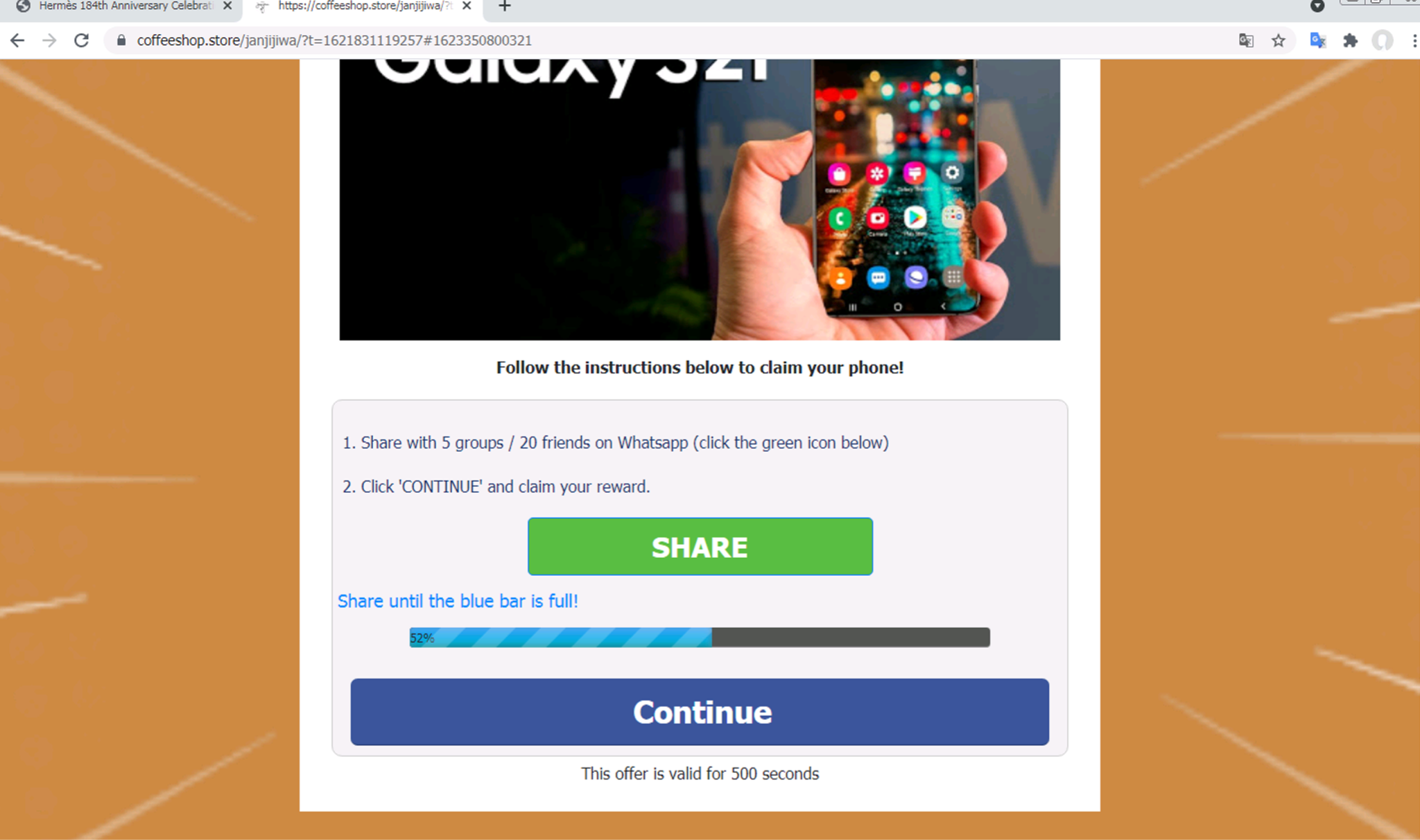
ユーザーがこのページを必要な数の友人と共有すると、ユーザーは最終的な登録ステップを完了するよう促されます。おそらく、被害者が「Complete registration(登録を完了する)」をクリックすると、機微情報を入力するように求めるフォームが表示され、そこに詐欺師が「無料のスマートフォン」(もちろん存在しない)を送れる、としているのでしょう。
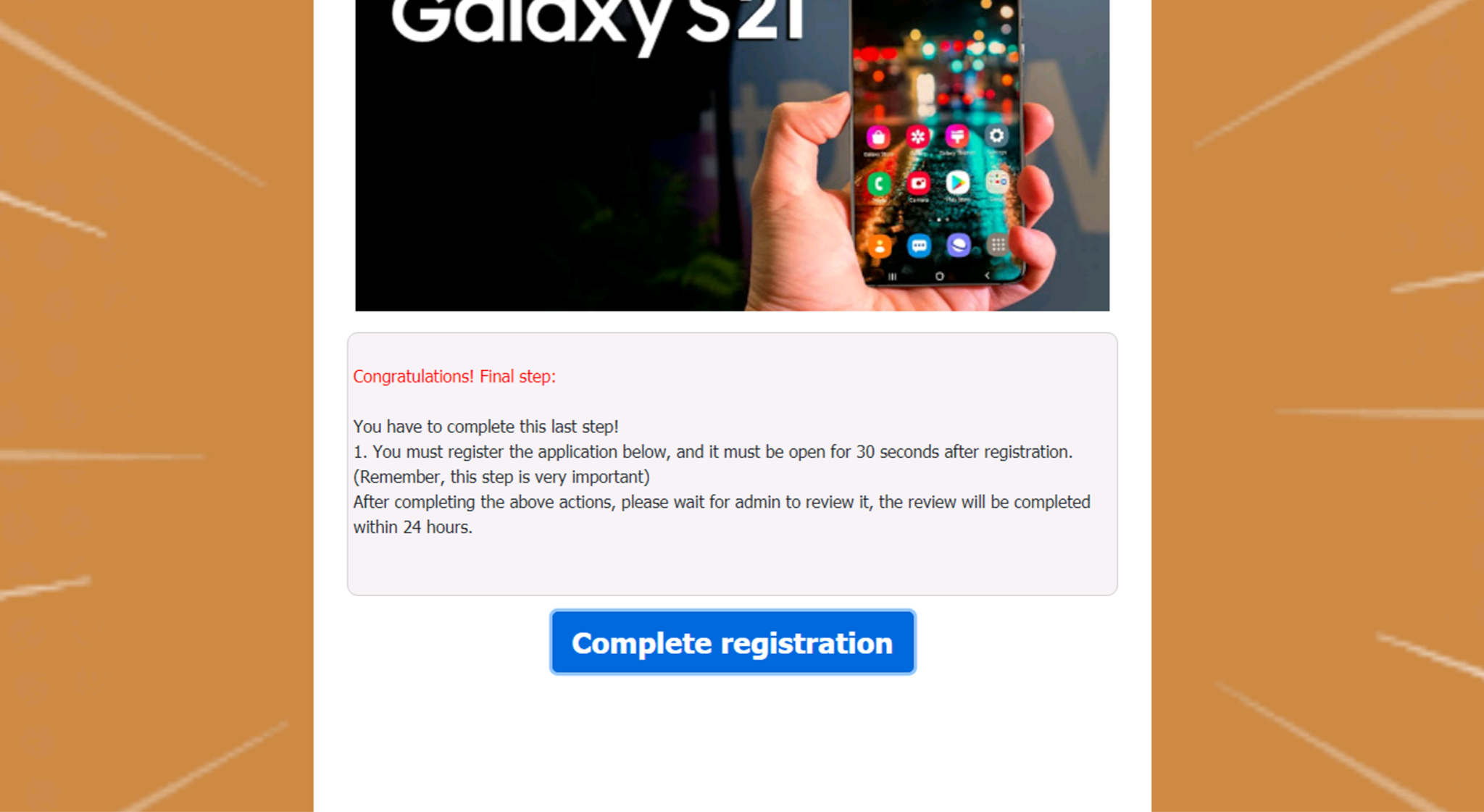
上の図で見られたように、この詐欺ページは非常に複雑なユーザーとのインタラクションを要求し、その後ようやく認証情報窃取フォームを表示します。ページのJavaScriptを分析し、深層学習でフィッシングや認証情報を奪取するアクティビティを示唆する疑わしいパターンを探すことで、これらのページをフィッシングとして検出し、お客様が実際にこの手の攻撃の餌食になることを防ぐことができます。
結論
従来のフィッシング検知エンジンでは、サイバー犯罪者が作成する巧妙化したフィッシングWebページを検知できないことがあります。具体的には、フィッシングページがユーザとのインタラクションを経てようやく実際のフィッシングコンテンツを表示したり、ページがブラウザで表示されるまで待ってからフィッシングコンテンツをHTML文書に注入するようなクライアントサイドクローキング事例を検出できないことが少なくありません。
Webページに含まれるJavaScriptを直接分析する深層学習モデル学習により、このようなJavaScriptを利用する巧妙なフィッシング攻撃を捕捉し、お客様の目に触れないようにすることができます。
パロアルトネットワークスの次世代ファイアウォールに搭載された機械学習援用のAdvanced URL Filteringサービスには、このJavaScriptベースのフィッシング検出機能が搭載されており、これらの攻撃からの保護に役立ちます。
IoC
- hxxps://appleid[.]uber[.]space
- cooking4kor[.]ru/cvfd/?onstoreid=40uti89763
- hxxps://555305[.]selcdn[.]ru
- hxxp://coffeeshop[.]store/janjijiwa
追加資料
謝辞
PhishingJSプロジェクトを最初から最後まで指導してくださったWei Wang氏、モデルのプロダクション環境への実装で協力してくださったWayne Xin氏とJingwei Fan氏、モデルのオリジナルアーキテクチャを提供してくださったBrody Kutt氏、モデルの検出結果のレビューに協力してくださったSeokkyung Chung氏、Yu Zhang氏、Zeyu You氏、Ziqi Dong各氏に感謝します。ありがとうございました。


 主なサイバー脅威
主なサイバー脅威


 脅威アクター グループ
脅威アクター グループ




