This post is also available in: English (英語)
概要
IT業界の大半がコンテナベースのインフラストラクチャ(クラウドネイティブ ソリューション)の導入を進める中、このテクノロジの限界を知ることが目下の課題となっています。
Docker、Linux Containers (LXC)、Rocket (rkt)といった従来型のコンテナはホストのOSカーネルを共有するため、完全にサンドボックス化されているとは言えません。これらはリソース効率が高い反面、攻撃対象領域が広く、特にさまざまな顧客が所有するコンテナが混在するマルチテナント型のクラウド環境ではその傾向が顕著です。
この問題の根本には、ホストOSがコンテナごとに仮想化されたユーザーランドを作成する場合のコンテナ間の分離の弱さがあります。そのため、完全にサンドボックス化されたコンテナの設計に重点を置いた研究開発が行われてきました。それらのソリューションの多くが、コンテナ間の境界を見直し、分離レベルを強化するというものです。本稿では、「コンテナの分離レベルを強化する」という同じ目標を達成する上で異なる手法を採用した、IBM、Google、Amazon、OpenStackによる4つの独創的なプロジェクトを紹介します。
それぞれ、Unikernelに基づいてコンテナを作成する「IBM Nabla」、コンテナを実行するための専用ゲスト カーネルを作成する「Google gVisor」、アプリケーションをサンドボックス化するための極めて軽量なハイパーバイザである「Amazon Firecracker」、コンテナ オーケストレーション プラットフォームに最適化された専用VM内にコンテナを配置する「OpenStack」です。その最先端の研究について本稿で示す概要は、読者の皆様が今後の変革に備えて準備を進める上できっとお役に立つでしょう。
従来型のコンテナ テクノロジの概要
コンテナとは、アプリケーションのパッケージ化、共有、展開を行うための最新の手法です。
すべての機能が1つのソフトウェアにパッケージ化されるモノリシックなアプリケーションとは対照的に、コンテナ化されたアプリケーションやマイクロサービスは、1つのジョブに特化した単一目的のために設計されています。
コンテナにはアプリケーションがそのタスクを実行するために必要なあらゆる依存関係(パッケージ、ライブラリ、バイナリなど)が含まれます。そのため、コンテナ化されたアプリケーションはプラットフォームに依存しないので、バージョンやインストールされたパッケージに関係なくどのオペレーティング システムでも直接実行できます。
この利便性によって、プラットフォームや顧客ごとにソフトウェアの各バージョンを調整する開発者の労力が大幅に軽減されます。必ずしも正しいとは言えませんが、概念上、コンテナは「軽量な仮想マシン」であると考えられがちです。
コンテナがホスト上に展開されると、各コンテナのファイル システムやプロセス、ネットワーク スタックといったリソースは、他のコンテナがアクセスできない仮想的に分離された環境内に配置されます。
このようなアーキテクチャでは、同じクラスタ上で数百から数千ものコンテナを同時に実行できるため、追加のコンテナ インスタンスをレプリケートすることで各アプリケーション(またはマイクロサービス)を容易にスケールアップすることが可能です。
詳しく見ていくと、コンテナ環境は2つの主要な構成要素である「Linux namespace (名前空間)」と「Linux Control group (cgroup)」に基づいています。名前空間は、仮想的に分離されたユーザー空間を作成し、アプリケーションにファイル システムやネットワーク スタック、プロセスID、ユーザーIDといった専用のシステム リソースを提供するものです。その分離されたユーザー空間では、アプリケーションがPID = 1から始まるファイル システムのルート ディレクトリを制御し、場合によってはルート ユーザーとして動作します。
このような抽象化されたユーザー空間によって、各アプリケーションは、同じホスト上の他のアプリケーションに干渉することなく独立して動作できるようになります。現在利用可能な名前空間は、「マウント」、「プロセス間通信(IPC)」、「Unixタイムシェアリング システム(UTS)」、「プロセスID(pid)」、「ネットワーク」、「ユーザー」の6つです。新たな名前空間として「時間」と「Syslog」の2つが提案されていますが、まだLinuxコミュニティでこれらの仕様の定義が進められているところです。
cgroupとは、特定のアプリケーションについてハードウェア リソースの制限や、優先順位、アカウンティング、制御を適用する機能であり、cgroupによって制御できるハードウェア リソースには、例えばCPUやメモリ、デバイス、ネットワークなどがあります。名前空間とcgroupを組み合わせることで、複数のアプリケーションを同一ホスト上で、各アプリケーションが個々の分離された環境内に存在する状態で安全に実行できます。これがコンテナの基本的な特性です。
仮想マシンとコンテナの主な違いは、VMがハードウェア レベルの仮想化であるのに対し、コンテナはOSレベルの仮想化であるという点です。VMハイパーバイザはVMごとにハードウェア環境をエミュレートしますが、コンテナ ランタイムはコンテナごとにオペレーティング システムをエミュレートします。また、VMはホストの物理ハードウェアを共有しますが、コンテナはハードウェアだけでなくホストのOSカーネルも共有します。コンテナはホストのリソースをより多く共有するため、ストレージ、メモリ、CPUサイクルのすべてにおいて、VMよりはるかに使用効率が高くなります。反面、共有するリソースが多いほどコンテナとホストの間の信頼境界が弱くなるという欠点もあります。図1は、コンテナとVMのアーキテクチャの違いを示しています。
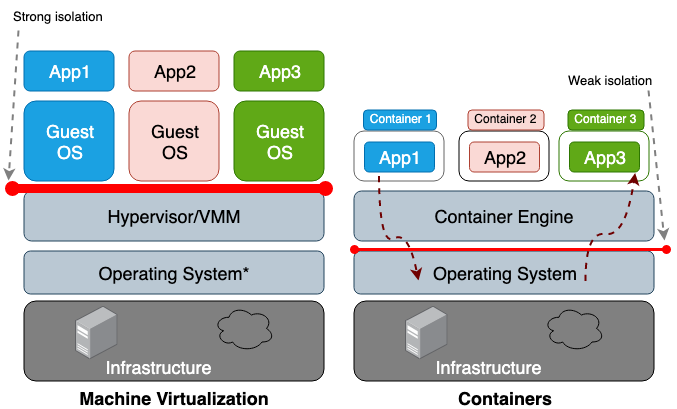
図1.マシンの仮想化では、ハイパーバイザ(仮想マシン モニタ(VMM)とも呼ばれる)によって各ゲストOS間の分離が行われるのに対し、コンテナでは、ホスト オペレーティング システムによって各コンテナ間の分離が行われる。
* オペレーティング システム上で実行される必要があるのはType II VMMのみ。Type I VMMは物理ハードウェア上で実行される
一般に、仮想化されたハードウェアの分離では、名前空間の分離よりも格段に強いセキュリティ境界が作成されます。攻撃者がコンテナ(プロセス)をエスケープするリスクは、VMをエスケープする可能性よりも大幅に高くなります。コンテナをエスケープするリスクの方が高いのは、名前空間とcgroupによって作成される分離が弱いためです。
Linuxでは、プロセスごとに新しいプロパティ フィールドを関連付けることで名前空間とcgroupを実装します。/procファイル システムの下にあるこれらのフィールドによって、特定のプロセスが他のプロセスを参照できるかどうかや、そのプロセスが使用できるCPU/メモリ割り当て量をホストOSに伝えます。ホストOSから実行中のプロセスやスレッドを(topコマンドやpsコマンドなどで)確認すると、コンテナ プロセスの見た目はホスト上の他のプロセスと変わりません。一般に、LXCやDockerといった従来型のコンテナは、同一ホスト上のコンテナ間で同じカーネルを共有することから、完全にサンドボックス化されているとは見なされません。したがって、コンテナからエスケープされる脆弱性が発見されても、何ら不思議なことではありません。
例えば、CVE-2014-3519、CVE-2016-5195、CVE-2016-9962、CVE-2017-5123、CVE-2019-5736などは、すべてコンテナからの脱出につながる可能性があります。カーネル エクスプロイトは通常、特権昇格へと発展して、侵害されたプロセスが意図された名前空間以外の制御を得られるようにするものであるため、その大半がコンテナをエスケープする機能を備えているはずです。ソフトウェアの脆弱性による攻撃ベクトルに加えて、必要以上の特権(CAP_SYS_ADMIN機能、特権的アクセス権など)や重要なマウント ポイント(/var/run/docker.sockなど)を持つコンテナを展開するといった不適切な構成は、どれもコンテナからのエスケープにつながることが考えられます。
このような悲惨な結果をもたらす可能性があることから、マルチテナント クラスタでコンテナを展開する場合や、機密データを含むコンテナを他の信頼できないコンテナと同じ場所に配置する場合のリスクを理解する必要があります。
これらのセキュリティ上の懸念が、研究者らをコンテナの信頼境界の強化へと駆り立てているのです。その目的は、できるだけホストOSから分離された、完全に「サンドボックス化された」コンテナを実現することにあります。ソリューションの多くには、VMの強力な信頼境界を活かしながら、コンテナのより高い効率性に注目した、ハイブリッド型のアーキテクチャを構築するアプローチが含まれます。
本稿の執筆時点では、標準化されるほど十分に成熟したプロジェクトは皆無ですが、将来的にこれらの魅力的な概念の一部がコンテナ開発に取り入れられるようになることは間違いないでしょう。以降では、この先有望なプロジェクトをいくつか取り上げ、それぞれの特徴を比較したいと思います。
まずは、「Unikernel」から紹介します。Unikernelは、アプリケーションを最小セットのOSライブラリと共に1つのイメージにパッケージ化する最も初期の単一目的マシンです。その概念は、安全でフットプリントの小さい、最適化されたマシン イメージの実現を目指す、将来の多くのプロジェクトにとって基盤となるでしょう。次に説明するのは、コンテナのようなUnikernelアプリケーションを実行することを目指す「IBM Nabla」プロジェクトと、コンテナをユーザー空間のカーネル上で実行する「Google gVisor」プロジェクトです。
これらのUnikernelに似た2つのプロジェクトの後は、VMベースのコンテナ ソリューションである「Amazon Firecracker」と「OpenStack Kata」の説明に移ります。最後のセクションでは、取り上げたすべてのプロジェクトを比較して本稿を締めくくりたいと思います。
Unikernel
仮想化テクノロジの進歩が、クラウド コンピューティングへの移行を可能にしました。Amazon Web Service (AWS)やGoogle Computing Platform (GCP)では、XenやKVMといったハイパーバイザが欠かせない構成要素として利用されています。近ごろのハイパーバイザは1つのクラスタ内で何百ものVMを処理できるとはいえ、従来の汎用オペレーティング システムに基づくVMは、仮想化環境での実行に最適化されていないことが一般的です。汎用OSはできるだけ多くの種類のアプリケーションをサポートすることを目的として設計されているため、そのカーネルには各種のドライバ、プロトコル ライブラリ、スケジューラが含まれています。
一方、現在クラウドで展開されている個々のVMの多くは、DNS、プロキシ、データベースといった特定のアプリケーションに専用で使用されています。各アプリケーションが利用するのはカーネルの機能のほんの一部なので、残りの使用されない機能によってシステム リソースが無駄になり、攻撃対象領域が拡大してしまいます。コードベースが大きいほど、対処すべき脆弱性やバグの数が増えるためです。このような問題が、コンピュータ サイエンティストが特定のアプリケーションだけをサポートする最小限のカーネル機能を備えた単一目的OSの設計を目指す根拠となっています。
オペレーティング システムの研究者らが「Unikernel」の概念を初めて提案したのは、1990年代のことです。Unikernelは、ハイパーバイザ上で直接実行できる、専用の単一アドレス空間のマシン イメージであり、アプリケーションとアプリケーションが依存するカーネル機能を1つのイメージにパッケージ化します。Unikernelの最も初期の学術プロジェクトとして、NemesisとExokernelの2つが挙げられます。図2は、Unikernelマシン イメージの作成と展開の仕組みを示しています。
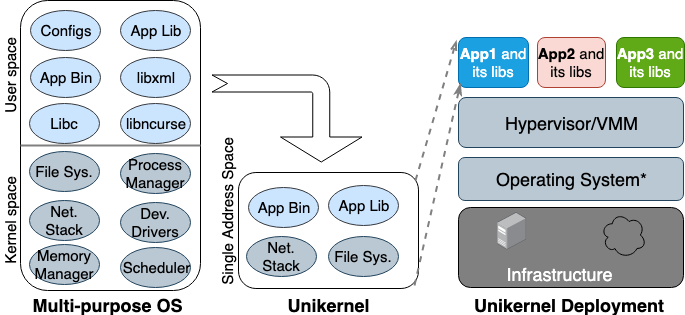
図2. 多目的OSは、あらゆる種類のアプリケーションをサポートする目的で構築されているため、多数のライブラリやドライバがプリロードされている。一方、Unikernelは、特定のアプリケーションをサポートする目的で設計された専用の単一目的OS
Unikernelは、カーネルを複数のライブラリに分け、アプリケーションが依存するライブラリだけを1つのマシン イメージに割り当てます。VMと同様、Unikernelの展開と実行も仮想マシン モニタ上で行われます。フットプリントが小さいため、Unikernelはブートやスケールアップに時間がかかりません。Unikernelの最も本質的な特性として、高いセキュリティ、小さなフットプリント、高度な最適化、高速なブートが挙げられます。Unikernelイメージにはアプリケーションが依存するライブラリだけが含まれ、特別に追加しない限りシェルは使用できないので、攻撃者が利用できる攻撃対象領域が最小限に抑えられます。
また攻撃者にとって、Unikernelは攻撃の足掛かりとすることが難しいばかりでなく、侵害の影響も1つのUnikernelインスタンスに限られます。イメージのサイズがわずか数メガバイトにとどまるUnikernelは、数十ミリ秒でブートでき、1つのホスト上で何百ものインスタンスを実行することが可能です。また、最近のOSの大半に含まれる多段ページ テーブルの代わりに単一アドレス空間でのメモリ割り当てを使用するUnikernelアプリケーションは、同じアプリケーションがVMで実行される場合よりもメモリ アクセスの待ち時間が短くなります。アプリケーションはイメージの作成時にカーネルを使ってコンパイルされるので、コンパイラはバイナリを最適化するためにより静的な型チェックを行うことができます。
Unikernelプロジェクトのリストは、Unikernel.orgで管理されています。これらすべての顕著な特性をもってしても、Unikernelはそれほど勢いに乗っているとは言えません。2016年にDockerがUnikernelを手掛けるスタートアップであるUnikernel Systemsを買収した際には、DockerがコンテナをUnikernelにパッケージ化するものと思われましたが、3年が経過した今も統合の兆しは一切見られません。
採用が遅れている主な理由の1つに、Unikernelアプリケーションを作成するための成熟したツールが存在せず、Unikernelアプリケーションを実行できるハイパーバイザが限られていることがあります。その上、アプリケーションをUnikernelに移植するには、異なる言語でコーディングをやり直す作業や、依存するカーネル ライブラリを手動で追加する作業が必要になることも考えられます。Unikernelでのモニタリングやデバッグは不可能か、そうでなくてもパフォーマンスに重大な影響を及ぼします。
このような制限がすべて、Unikernelへの移行を開発者がしり込みする原因となっています。ここで留意すべきは、Unikernelとコンテナの多くの特性が似ているという点です。Unikernelとコンテナはどちらも不変の単一目的イメージなので、イメージ内のコンポーネントを更新することやパッチを適用することができず、アプリケーションが更新されるたびに新しいイメージが作成されることになります。現在のUnikernelは、まるでコンテナ ランタイムが提供されておらず、開発者が基本の構成要素(chroot、unshare、cgroup)を使ってアプリケーションをサンドボックス化する必要があったDocker以前の時代のようです。
IBM Nabla
IBMの研究者チームが提案した「Unikernel as Process」の概念は、専用の仮想マシン モニタ上でUnikernelアプリケーションをプロセスとして動作させるというものです。IBMの「Nabla containers」プロジェクトでは、汎用モニタ(QEMUなど)がUnikernel専用モニタのNabla Tenderに置き換えられるため、Unikernelの信頼境界が一層強化されます。なぜなら、Unikernelと汎用仮想マシン モニタ(VMM)の間のハイパーコールによって生まれる大きな攻撃対象領域も、許可されるシステム コールの数が少ないUnikernel専用モニタを使用することでセキュリティを大幅に強化できるためです。Nabla Tenderは、UnikernelがVMMに送信するハイパーコールを取得し、それをシステム コールに変換します。Tenderが必要としない他のシステム コールは、Linuxのseccompポリシーがすべてブロックします。UnikernelはNabla Tenderと共にホスト上でユーザー空間のプロセスとして動作します。図3は、NablaがUnikernelアプリケーションとホストの間に薄いインターフェイスを作成する仕組みを示しています。
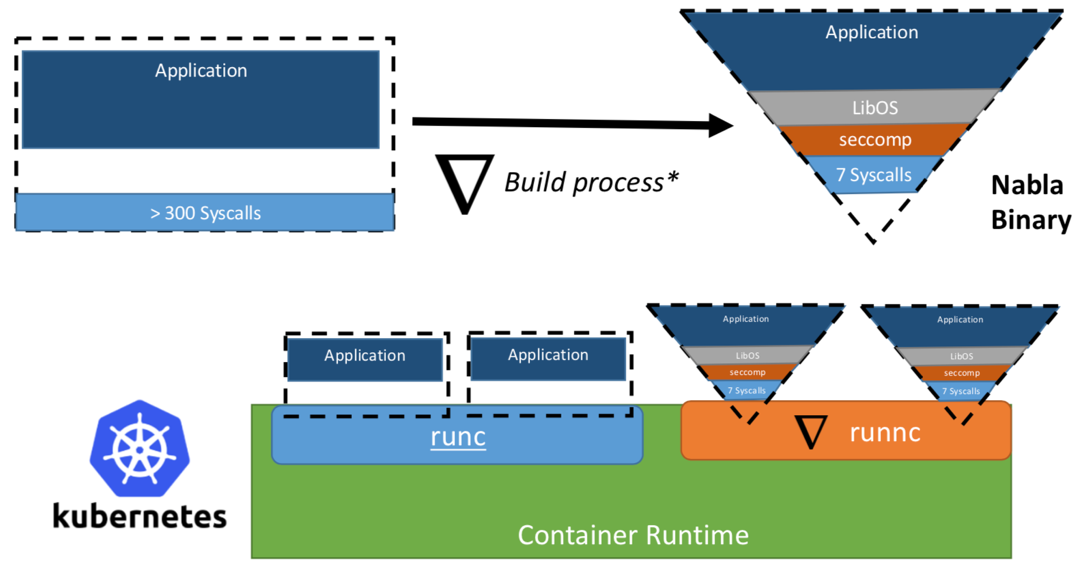
図3. Nablaは、既存のコンテナ ランタイム プラットフォームと接続するためにDockerやKubernetesなどのプラットフォームに接続できるOCI準拠のランタイムであるrunncを実装している。
画像の出典: Unikernels as Process
研究チームによると、Nabla Tenderがホストとの接続に使用するシステム コールの数は7つ未満だということです。システム コールはユーザー空間のプロセスとOSカーネルをつなぐ架け橋として機能するため、使われるシステム コールが少ないほど、カーネルにさらされる攻撃対象領域は小さくなります。Unikernelをプロセスとして動作させることには、Unikernelアプリケーションをほとんどのプロセスベース ツール(gdbなど)を使ってデバッグできるという利点もあります。
またNabla は、コンテナ オーケストレーション プラットフォームを利用するために、Open Container Initiative(OCI)標準を実装するNablaランタイムである runncを提供しています。OCI標準では、ランタイム クライアント(Docker、Kubectlなど)とランタイム(runcなど)の間のAPIが規定されています。ほかにも、Nablaは、runncによって実行できるUnikernelイメージを作成するためのイメージ ビルダーも提供しています。Unikernelと従来型コンテナにはファイル システムに違いがあるため、NablaのイメージはOCIのイメージの仕様に従っておらず、Dockerイメージはrunncに対応していません。本稿の執筆時点では、このプロジェクトはまだ初期の実験段階です。その他の制限としては、ホスト ファイル システムのマウント/アクセス、複数のネットワーク インターフェイスの追加(Kubernetesで必要)、他のUnikernelイメージ(MirageOS、IncludeOSなど)からのイメージの使用をサポートしていないといった制限があります。
Google gVisor
Google gVisorは、Google Computing Platform(GPC)のApp Engine、Cloud Functions、CloudMLで利用されているサンドボックス テクノロジです。Googleは、信頼されていないアプリケーションをパブリック クラウド インフラストラクチャで実行するリスクや、VMを使ってアプリケーションをサンドボックス化することの非効率性に気付き、信頼されていないアプリケーションをサンドボックス化するユーザー空間のカーネルを開発しました。gVisorは、アプリケーションからホスト カーネルへのシステム コールをすべて取得し、それらをgVisorのカーネルの実装であるSentryを使ってユーザー空間で処理することで、アプリケーションをサンドボックス化します。基本的には、ゲスト カーネルとVMMの組み合わせとして機能します。図4は、gVisorのアーキテクチャを示しています。
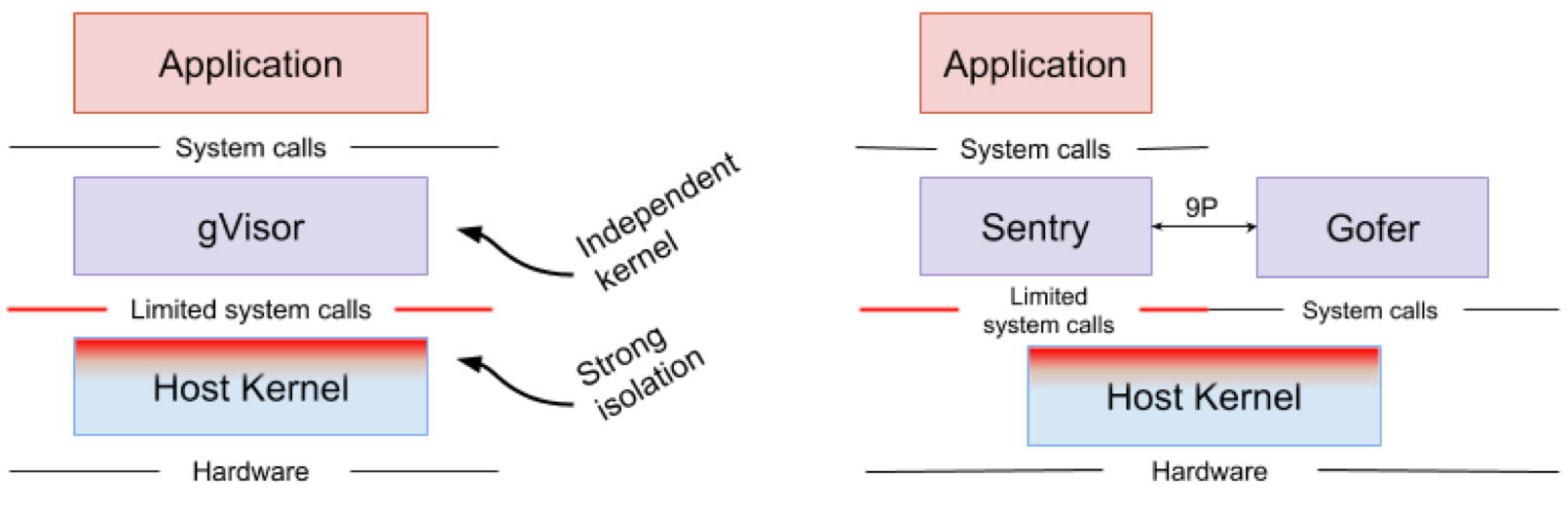
図4. gVisorカーネルの実装であるSentry とgVisorファイル システムの実装であるGoferがホストと接続するために使うのはシステム コールのごく一部。
画像の出典: gVisorのアーキテクチャ ガイド、gVisorの概要とプラットフォーム
gVisorは、アプリケーションとそのホストの間に強力なセキュリティ境界を構築します。その境界によって、ユーザー空間のアプリケーションが使用できるシステム コールが制限されます。仮想化されたハードウェアを利用しないgVisorは、サンドボックス化されたアプリケーションとホストを接続するホスト プロセスとして動作します。
Sentryは、Linuxシステム コールと基本のカーネル機能(シグナルの送信、メモリ管理、ネットワーク スタック、スレッド モデルなど)の大半を実装しています。Sentryには、サンドボックス化されたアプリケーションをサポートするため、319種類あるLinuxのシステム コールのうち70%以上が実装されました。Sentryがホスト カーネルと通信するために使用するLinuxのシステム コールは、20種類を切ります。注目すべき点は、gVisorとNablaが「ホストOSを防御する」という非常によく似た戦略をとっているということです。どちらもホスト カーネルとの接続に使用するのはLinuxのシステム コールの10%未満です。gVisorが多目的カーネルを作成するのに対し、NablaはUnikernelを使用しますが、両者ともサンドボックス化されたアプリケーションをサポートするためにユーザー空間の専用ゲスト カーネルを実行します。
オープンソースのLinuxカーネルが容易に入手できるにもかかわらず、gVisorが別のLinuxカーネルを再実装する必要があることに疑問を感じる方もいらっしゃるでしょう。それは、強い型安全性とメモリ管理機能を備えたGolang言語で書かれたgVisorのカーネルは、C言語で書かれたLinuxカーネルよりも安全であるためです。gVisorの重要なセールス ポイントとしては、ほかにもDocker、Kubernetes、OCI標準との緊密な統合が挙げられます。Dockerイメージのほとんどは、ランタイムをgVisorのrunscに変えることで、gVisorを使って簡単に取得して実行することが可能です。Kubernetesでは、各コンテナをサンドボックス化するのではなく、ポッド全体をgVisorのサンドボックス内で実行できます。
gVisorはまだ初期段階にあることから、今なおいくつかの制限があります。サンドボックス化されたアプリケーションによって作成されたシステム コールをgVisorが取得して処理する際には必ずオーバーヘッドが生じるため、gVisorはシステム コールを大量に作成するアプリケーションには適していません(このようなオーバーヘッドは、Unikernelアプリケーションがシステム コールを作成しないNablaでは発生しません。Nablaがハイパーコールの処理に使用するシステム コールは7種類のみです)。gVisorはハードウェアに直接アクセス(パススルー)することができないため、GPUなどのハードウェアへのアクセスを必要とするアプリケーションはgVisorで実行できません。最後に、gVisorにはLinuxのシステム コールがすべて実装されているわけではないため、実装されていないシステム コールを使用するアプリケーションをgVisorで実行することはできません。
Amazon Firecracker
Amazon Firecrackerは、AWS LambdaとAWS Fargateで現在利用されているテクノロジであり、特にマルチテナント型のコンテナやサーバーレス型の運用モデル用に軽量の仮想マシン(microVM)を作成するVMMです。Firecrackerが提供される以前は、強力な分離レベルを確保するために、各顧客専用のEC2 VM内でLambda関数とFargateコンテナが実行されていました。パブリック クラウドではVMがコンテナの強力な分離を実現しますが、アプリケーションをサンドボックス化するために汎用VMMとVMを使用する方法は、あまりリソース効率が高くありません。一方、Firecrackerなら、クラウドネイティブ アプリケーション専用のVMMを作成するため、セキュリティとパフォーマンスの課題を同時に解決できます。FirecrackerのVMMは、ゲストVMごとに最小限のOS機能とエミュレートされたデバイスを提供するので、セキュリティとパフォーマンスの両方を強化することが可能です。ユーザーは、Linuxカーネルのバイナリとext4ファイル システム イメージを使ってFirecracker上で動作するVMイメージを簡単に作成できます。AmazonはFirecrackerの開発を2017年に開始し、2018年にオープン ソース化しました。
Unikernelの概念と同様、コンテナの運用をサポートするためにプロビジョニングされるのは、デバイスと機能のごく一部のみです。従来型のVMと比べ、microVMの攻撃対象領域とメモリ フットプリントは格段に小さく、ブート時間もはるかに高速です。こちらの評価で、CPU 2基と256GBのRAMが搭載されたホスト上でFirecrackerのmicroVMを実行した場合に、メモリが5MB以下、ブート時間が125ミリ秒以下になることが証明されています。図5は、Firecrackerのアーキテクチャとそのセキュリティ境界を示しています。
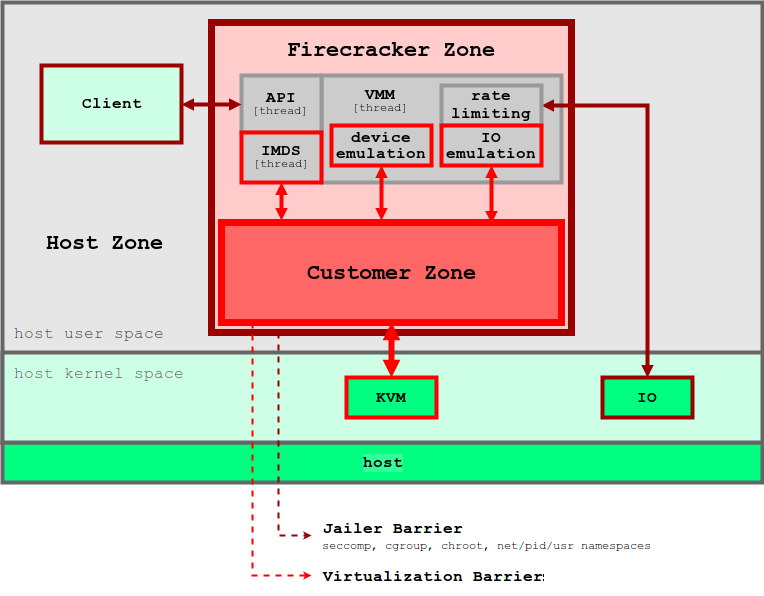
図5. FirecrackerのVMMでは、各ユーザーのアプリケーションを分離するためにセキュリティ境界が多層的に適用される
画像の出典: Firecracker Design
FirecrackerのVMMはKVMを利用し、各Firecrackerインスタンスがユーザー空間のプロセスとして動作します。各Firecrackerプロセスは、システム コール、ハードウェア リソース、ファイル システム、ネットワーク アクティビティを厳しく制限するために、seccomp、cgroup、namespaceポリシーによってロックダウンされます。各Firecrackerプロセス内には複数のスレッドが含まれます。
APIスレッドは、ホスト上のクライアントとmicroVMの間にコントロール プレーンを提供し、VMMスレッドは、最小限のvirtIOデバイス(netとblock)のセットを提供します。Firecrackerでは、エミュレートされたデバイスがmicroVMごとに4つ(virtio-block、virtio-net、serial console、1-button keyboard controller)のみプロビジョニングされ、microVMを停止するためだけに使用されます。セキュリティ上の理由から、VMにはホストとファイルを共有するためのメカニズムはありません。コンテナ イメージなどのホスト上のデータは、ファイル ブロック デバイスを通してmicroVMに伝達されます。VMのネットワーク インターフェイスは、ネットワーク ブリッジを介してtapデバイスによってバックアップされます。送信パケットはすべてtapデバイスにコピーされ、cgroupポリシーによって速度が制限されます。このような多層的なセキュリティ境界によって、特定のユーザーのアプリケーションが他のユーザーのアプリケーションを妨げる可能性を最小限に抑えます。
本稿の執筆時点では、FirecrackerはまだDockerやKubernetesと完全に統合されていません。Firecrackerはハードウェア パススルーをサポートしていないので、GPUや何らかのデバイス アクセラレータへのアクセスを必要とするアプリケーションには適していません。VMとホストの間のファイル共有およびネットワーキング モデルも制限されています。ただし、このプロジェクトは大規模なコミュニティによって支持されているため、近くOCI標準への適合が行われ、より多くのアプリケーションがサポートされるはずです。
OpenStack Kata
従来型のコンテナが抱えるセキュリティ上の懸念を受け、Intelは独自のVMベース コンテナ テクノロジ「Clear Containers」を2015年に公開しました。Clear Containersは、Intel® VTハードウェアに基づく仮想化テクノロジと高度にカスタマイズされたQEMU-KVMハイパーバイザのqemu-liteを利用して、パフォーマンスの高いVMベースのコンテナを実現するためのものです。2017年末、Clear ContainersプロジェクトはHyper RunV(OCIに対応したハイパーバイザベースのランタイム)と共同で、Kata Containersプロジェクトを開始しました。Clear Containersのすべての特性を引き継いだKata Containersは、より幅広いインフラストラクチャとコンテナ仕様をサポートするようになっています。
Kata Containersは、OCI、CRI (Container Runtime Interface)、CNI (Container Networking Interface)と完全に統合されています。各種のネットワーキング モデル(passthrough、MacVTap、bridge、tc mirroring)と構成可能なゲスト カーネルをサポートしているため、特別なネットワーキング モデルやカーネル バージョンを必要とするアプリケーションもすべてKata Containers上で実行できます。図6は、Kata VM内のコンテナが既存のオーケストレーション プラットフォームと接続する仕組みを示しています。
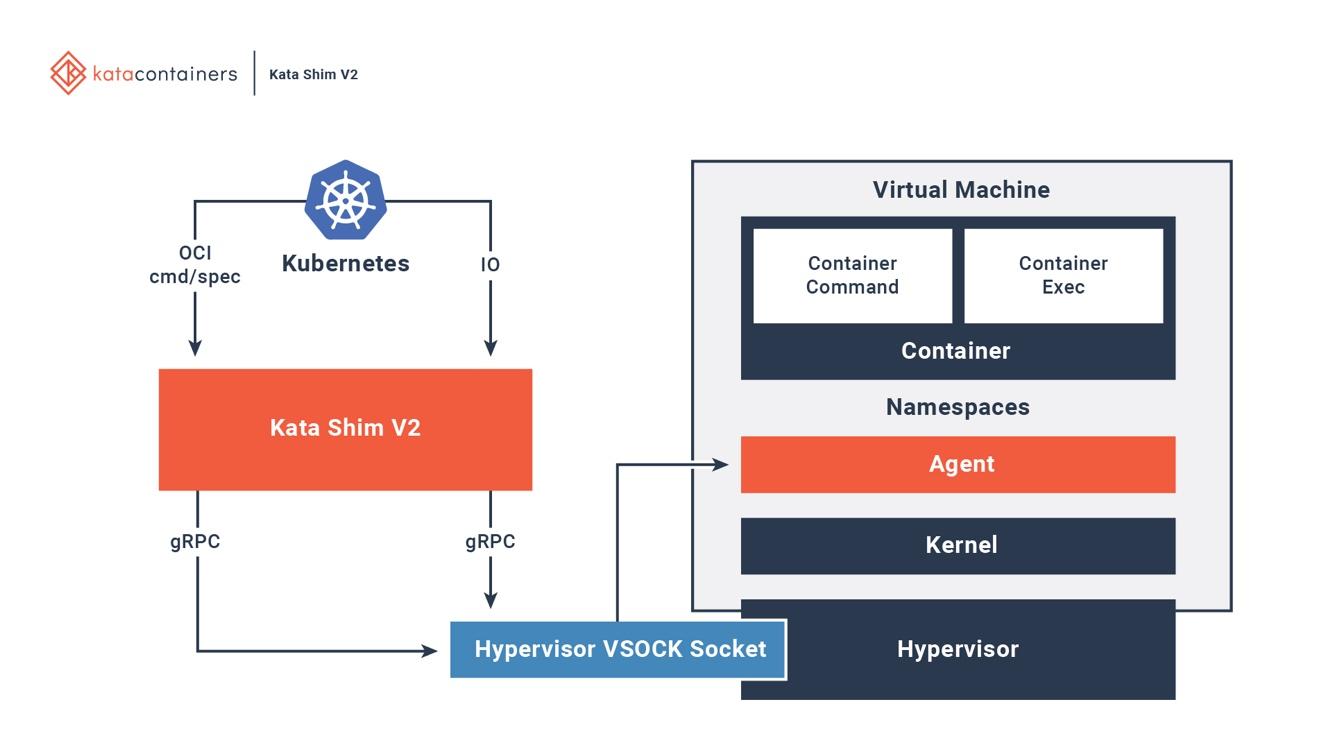
図6. Kata ContainersはDockerやKubernetesと完全に統合されている
画像の出典: Kata Containersプロジェクトの概要
Kataは、ホスト上に新しいコンテナの開始や構成を行うためのkata-runtimeを備えています。Kata VM内の各コンテナごとに、対応するKata Shimがホスト上にあります。Kata Shimは、クライアント(docker、kubectlなど)からAPI要求を受け取り、VSockを通してそれらの要求をKata VM内のエージェントに転送します。Kata Containersはさらに、VMのブート時間を短縮するためにいくつかの最適化を行います。NEMUは、最大80%のデバイスとパッケージが削減されたQEMUの軽量バージョンです。VM-Templatingによって、実行されているKata VMインスタンスの複製が生成され、その複製が他の新たに作成されたKata VMと共有されます。これにより、ブート時間が大幅に短縮されると共に、ゲストVMのメモリ消費量がかなり削減されますが、 CVE-2015-2877のようなVM間のサイドチャネル攻撃に弱い場合があります。Hotplug機能を使用することで、VMのブートを最小のリソース(CPU、メモリ、virtio block)で行ったり、必要に応じて後からリソースを新たに追加したりすることができます。
Kata ContainersとFirecrackerは、どちらもクラウドネイティブ アプリケーション用に設計されたVMベースのサンドボックス テクノロジで、同じ目標を共有しますが、そのためのアプローチは大きく異なります。FirecrackerがゲストOS用に安全な仮想化環境を確立するための専用VMMであるのに対し、Kata Containersはコンテナを実行するために高度に最適化されたVMです。これまで、FirecrackerのVMM上でKata Containersを実行するためにさまざまな努力が行われてきました。そのプロジェクトはまだ実験段階ですが、2つのプロジェクトが持つ最高の特長を兼ね備えたものになることが期待されます。
結論
本稿では、従来型のコンテナ テクノロジが抱える問題である分離レベルの弱さに対処するためのソリューションをいくつか見てきました。
アプリケーションを専用のVMにパッケージ化するUnikernelベースのソリューションである「IBM Nabla」。アプリケーションとホストを安全に接続するために専用のハイパーバイザとゲストOSカーネルを組み合わせる「Google gVisor」。ゲストOSごとに最小セットのハードウェアとカーネル リソースをプロビジョニングする専用ハイパーバイザの「Amazon Firecracker」。そして、ハイパーバイザ上で実行できるコンテナ エンジンが組み込まれた高度に最適化されたVMである「OpenStack Kata」です。
それぞれ長所と短所が異なるので、どれが一番だと言うことは難しいため、表1に4つすべてのプロジェクトの重要な特長を比較できるようまとめました。
Nablaは、MirageOSやIncludeOSなどのUnikernelで実行されるアプリケーションがある場合に最適です。
gVisorは、現在DockerやKubernetesと最も緊密に統合されていますが、システム コールの実装が不十分であることから、今も一部のアプリケーションを実行できない状態です。
Firecrackerは、カスタマイズされたゲストOSイメージをサポートしているため、カスタマイズされたVMでアプリケーションを実行する必要がある場合に選択するとよいでしょう。
Kata Containersは、OCI標準に完全に準拠しており、KVMとXenのどちらのハイパーバイザでも実行可能です。これにより、ハイブリッド プラットフォーム環境でのマイクロサービスの展開を簡素化できます。
いずれかまたは複数のソリューションが最終的に主流に乗るにはある程度時間がかかるかもしれませんが、多くのクラウド プロバイダがこの問題の軽減に乗り出していることは明らかです。オンプレミスのクラウドネイティブ プラットフォームの構築を進めている組織にとって、この状況は悲観すべきものではありません。迅速なパッチの適用、最小権限に基づく構成、ネットワーク セグメンテーションといった一般的な方法は、どれも攻撃対象領域を縮小するのに効果的です。
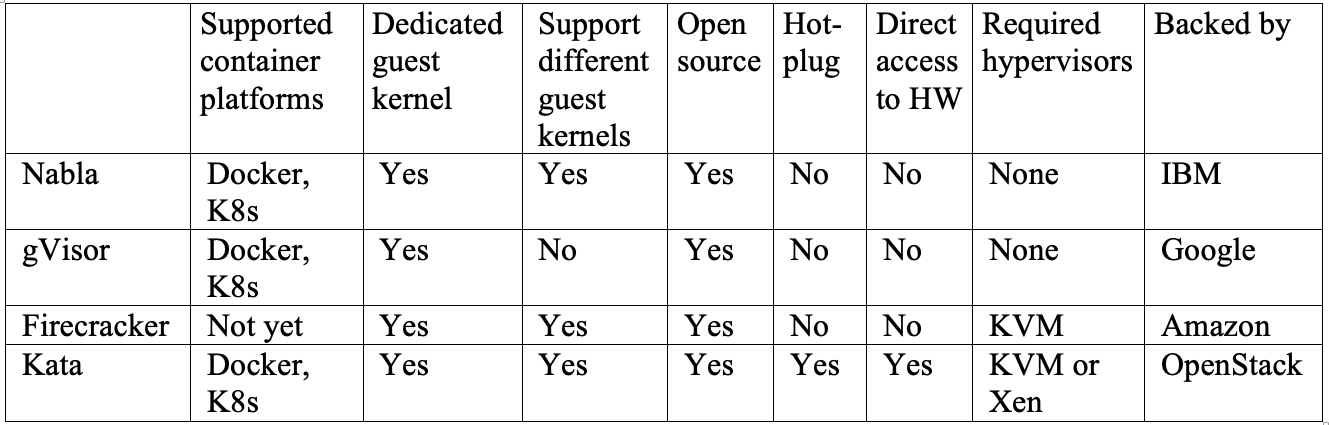
表1.4つすべてのプラットフォームの比較
目次
関連項目 リソース


 主なサイバー脅威
主なサイバー脅威



 脅威アクター グループ
脅威アクター グループ




{kind=link}