This post is also available in: English (英語)
概要
このブログ記事は、前回の記事HancitorのVBドロッパーおよびシェルコードが攻撃増加の背後に潜む新しい技法を明らかにの続編です。前回では、新型Visual Basic (VB)マクロ ドロッパーとそれに付随するシェルコードを分析しました。シェルコードがどこから始まっているか突き止め、Microsoft Word文書からバイナリを復号化したところで前回は終わっていました。
アナリストは、専用にデコーダを書きたくなるような埋め込みペイロードに遭遇することがありますが、その多くの場合、アナリストは自分が選んだ言語でアセンブリのアルゴリズムを単純に書き直し、ファイルを処理します。そうしたアルゴリズムの複雑さは、書き換えようとする際、マシン コードから高水準言語に至るまでいろいろと変わります。飲んだコーヒーの量やアルゴリズムの複雑度にもよりますが、ときにはもどかしくてたまらくないということもあり得ます。
今回の記事では、CPUエミュレーションとの組み合わせになっている攻撃者自身の復号化アルゴリズムを利用してペイロードを復号化または暗号解除することが、どのようにすれば目の前にあるアセンブリを再利用するだけでいとも簡単にできるのか、その方法をご紹介します。具体的には、PythonのUnicorn Engineモジュールを使って、攻撃者の復号化関数をエミュレート環境内で実行して、符号化済みペイロードを抽出することに焦点を当てます。最終目標は、最終的なHancitorペイロードが利用しているコマンド アンド コントロール(C2)サーバを、Microsoft Word文書処理用のPythonスクリプトを実行することで突き止めることです。
ところで、読者はそもそもこうしたことに何故悩むのか疑問に思われるかもしれません。前回の記事では、単にプログラムを実行させてペイロードをディスクに書き込んだので簡単に回収できたではないか。それなのに何故悩むのか、と。それに対して一番要となる答えは、大量分析の自動化です。文書ファイルでいっぱいのディレクトリを指し示してくれるプログラムを書くことができれば、C2抽出用の埋め込みペイロードを迅速に抽出し構文解析をして、現在取り組み中のことについて全体な見方をさらに広くすることができます。このような大量分析の例は、今年のはじめにLuminosityLinkマルウェア サンプルの大規模なサンプル セットを調査したときにご紹介しました。
復号化ルーチン
復習ですが、前回のブログ記事では下記のサンプルを調べていました。
03aef51be133425a0e5978ab2529890854ecf1b98a7cf8289c142a62de7acd1a
図1が示す復号化ルーチンを突き止めた後で終わりにしていましたが、そこから続けます。loc_B92の関数は各バイトに対して0x3を加え、その結果に対して0x13を使ってXOR演算を行います。埋め込みバイナリ内のすべてのバイトが処理されてしまうと、関数はこの埋め込みバイナリの位置をスタックにプッシュし、関数sub_827を呼び出します。
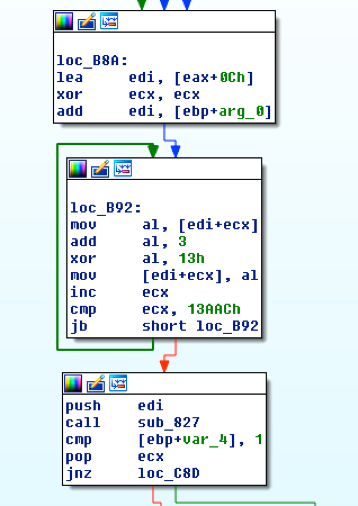
復号化ルーチンの詳細に立ち入ることはせず、このルーチンに対して5つの部品が存在すること、そして各部品が何らかの方法でバイトを操作してから関数全体が終わり、ペイロードが復号化された状態になることを承知しておきましょう。
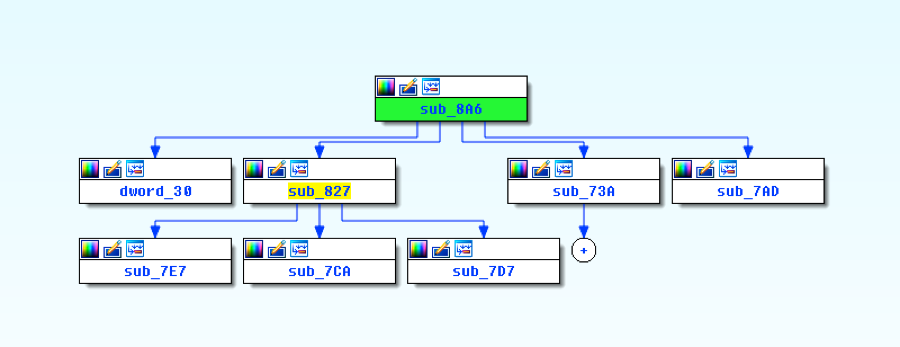
実質的にしようとしているのは、sub_8A6、sub_827、sub_7E7、sub_7CAおよびsub_7D7からバイトをコピーすることですが、これらは復号化のすべてを取り仕切る中心的な関数です。さらに、埋め込みペイロードが必要になります。このペイロードは前回のブログで考察したように、マジック ヘッダーの“POLA”によってWord文書の中で見つけることができます。
コピーしたバイトを取得したら、エミュレーション環境をセットアップし、アセンブリを調整してから、独自のシェルコードを実行してペイロードを取得します。このブログの主旨に沿って、わかりやすくするために、x86命令のみをシェルコードと呼ぶことにします。
オフセット0xB92から始まる、呼び出し直後までの2ブロックのバイトをコピーします。ペイロードのデコードはその部分によって行われるためです。
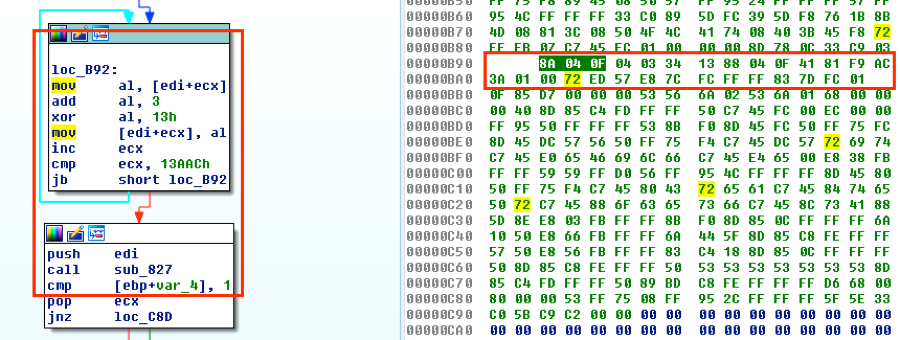
次に、sub_827から、オフセット0x827から0x8A5までの全バイトをコピーします。
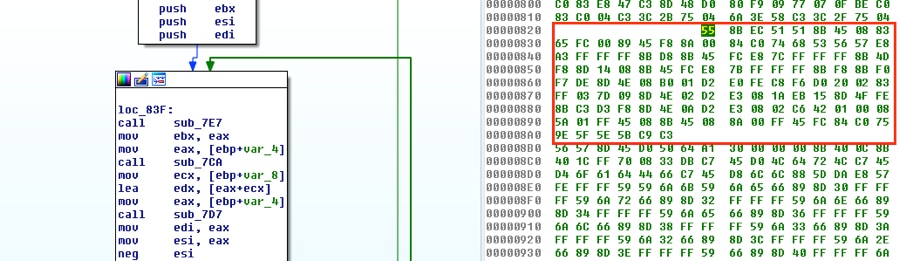
最後に、3つのより小さな関数からバイトを収集します。それらの場所に注意すれば、連続していることがわかります。それらのバイトの順序をそのまま維持しておくと便利ですが、必ずしも必要ではありません。順序どおりに並んでいなくても、適切な順序になるように呼び出しやジャンプのオペランドを調整するだけです。
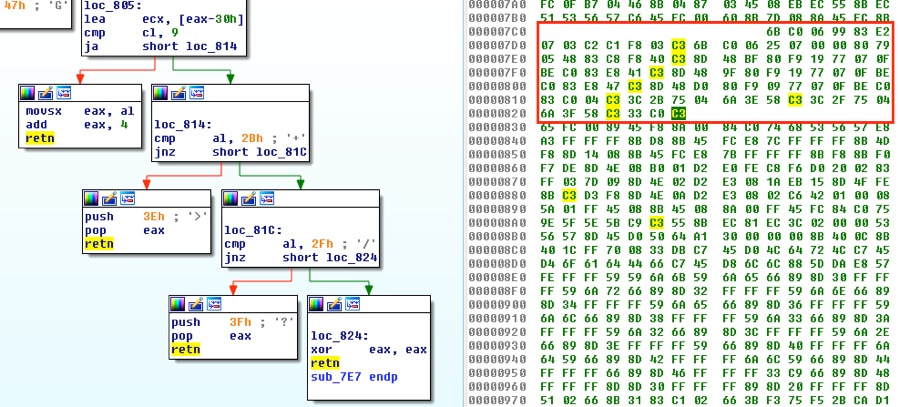
すべてのバイトを保存したら、それらをファイルに書き込み、逆アセンブラで開いて、修正するべき問題があれば、その箇所を確認できます。
シェルコードを見ると、主要な問題は1つだけです。それは別のアドレスにあるデコード関数に対する最初の呼び出しです。
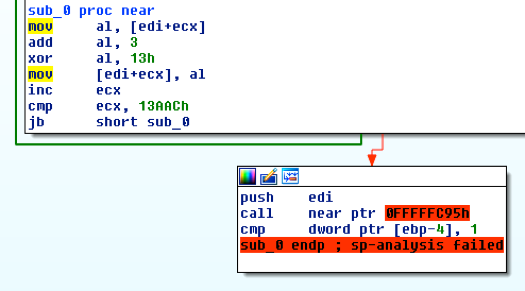
前の関数sub_827を呼び出したい場合、その関数はシェルコードの最後にあるため、その関数の先頭を指すように呼び出しを調整します。16進エディタでコードを見ると、関数はシェルコード内で正確に97バイト(0x61)から始まっているため、命令0xE87CFCFFFFを0xE861000000に変更します。

次に、逆アセンブラで変更が期待通りうまく動作すること、また関数がすべて正常にリンクされたことを検証できます。
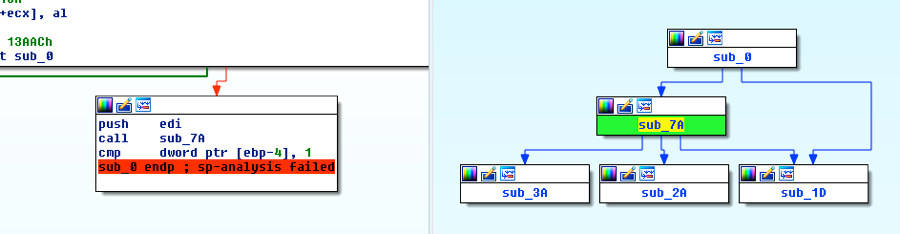
埋め込まれているペイロード
埋め込まれているペイロードのアドレスが、前の動的分析によって、スタックに押し込まれているEDIレジスタ上にあることがわかっています。この方法を最初に検証するために、先に進んで、POLAというマジック ヘッダーから始まる、0x13AAACバイト サイズのバイトを、Pythonスクリプトに手動でコピーします。ブログの最後で、このバイナリをWord文書から自動的に抽出するスクリプト全体を組み込みます。
Unicornの準備
これでバイナリをデコードする必要がある、すべてのデータを取得したので、このパートで最後にやるべき手順は、コード実行用のエミュレーション環境を構築することです。そのためにオープンソースのUnicornエンジンを使用します。
最初に作業用のアドレス スペースを割り当てます。また、エミュレートしたいアーキテクチャ (x86)用にUnicornを初期化し、使用するメモリをマッピングします。次に、メモリ領域にシェルコードとエンコードされたバイナリを書き、一部の値を初期化します。最後に、復号化されたデータをSTDOUTに出力します。
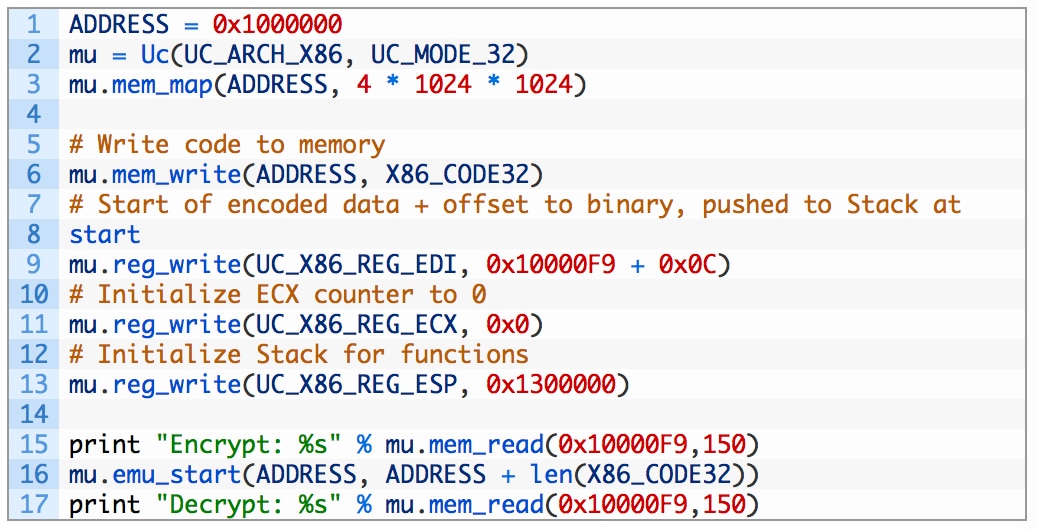


残念ながら、実際のHancitorサンプルを含むと思われるパック処理されたバイナリがあるため、さらに別のペイロードをデコードする必要があります。

バイナリの攻撃
このバイナリには、かなり大量の関数とコードが含まれますが、非常に早い時期に、バイナリが以前のブログ投稿で説明したものと同じAPI、RtlMoveMemory()のアドレスを検索することがわかっています。その後、私たちが推測したコピーがエンコードされたペイロードです。
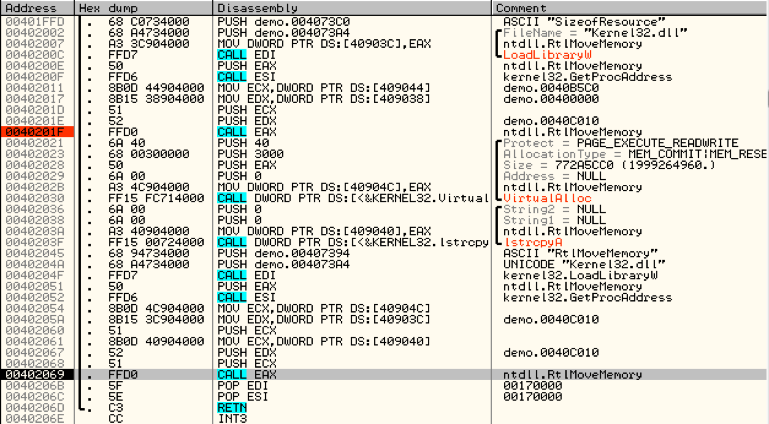
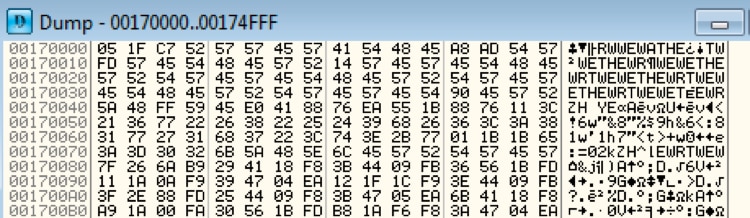
プログラムのデバッグを続けていくと、後から、次のデコード ルーチンのような3つの命令のみが返されます。
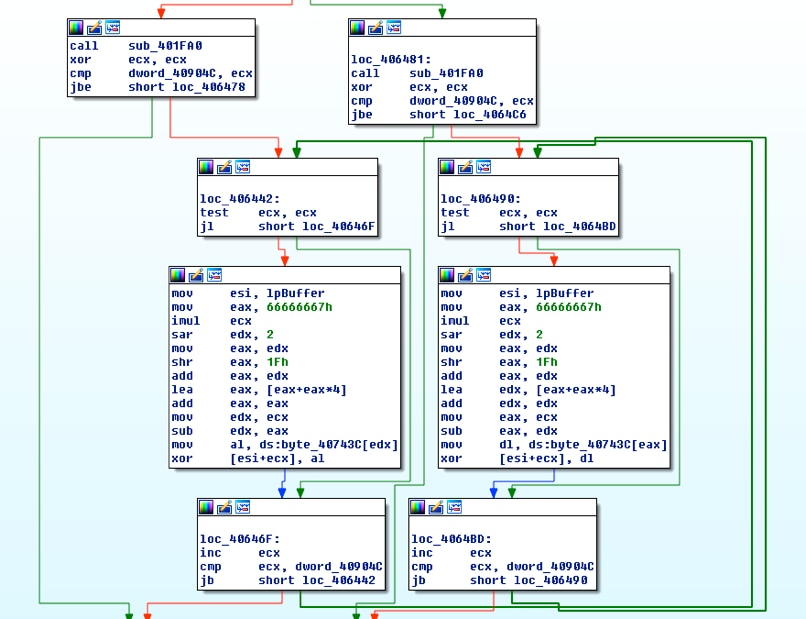
すばやくMZ実行可能ヘッダーを識別するために、これらのブロックをそのままにして、自分たちが適切な箇所にいることを何度か検証します。

これで、RtlMoveMemory()によって、エンコードされたバイナリの場所と、エミュレートする必要がある関数の場所がわかりました。
関数Copying
この関数を分析すると、最後の関数ほど複雑ではありませんが、例では0x40743Cにある12バイト キーを順に処理する際に異なるアプローチを採っており、それを使用してエンコードされたペイロードをXORしています。

以前と同じ方法論に従って、それをプログラムに追加します。
loc_406442から始め、デコード ループである下図の3つのブロックのすべてのバイトをコピーします。
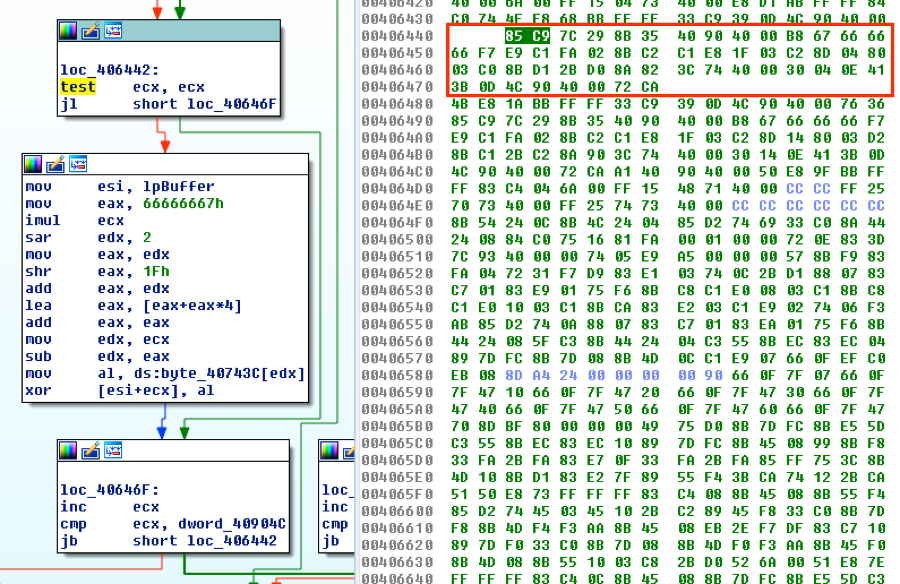
次に、XORキーとエンコードされたペイロードをスクリプトにコピーし、それが次の動作順序に従うように、テスト ファイルを作成します。
シェルコード -> キー -> ペイロード
逆アセンブラでコードを見ると、このコードをエミュレートされた環境で実行できるようにするために、事前に準備する必要のあるいくつかの値があることがわかります。特に、私たちのコード内に存在しない場所を参照している2つのMOV命令と1つのCMP命令を編集する必要があります。
動的な分析に基づくと、lpBufferがエンコードされたペイロードのアドレスを示すポインタであることがわかります。そのため、この命令を変更して、ペイロードが存在する開始位置をESIレジスタに移動できます。現在の命令は、ペイロードへのアドレスを保持するデータ セグメント内のアドレスを参照しています。0x8B3540904000を0xBE42000190に変更することで、それをイミディエイトMOV命令で置き換えます。ここでは、0x100042がバッファの始点です。オペコードを変更して、新しい命令の長さが1バイト短くなったため、それを0x90 – NOPで埋め、すべてアラインされたまま保持します。
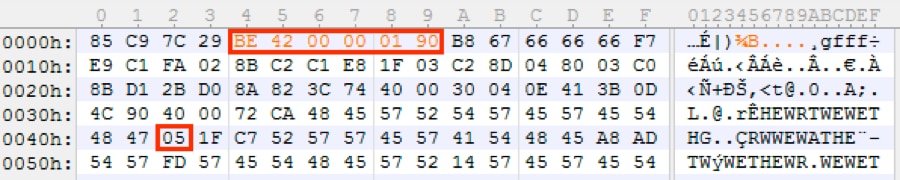
最初のMOVはエンコードされたペイロードに対応し、2番目のMOVはXORキーに対応します。2番目のMOVは、私たちのニーズにより都合の良い異なるオペコードを使用します。そのため、0x8A823C744000を値0x8A8236000001に変更することで、既存のアドレスをキーの位置に簡単に変更できます。

最後に変更する項目は、比較命令です。動的な分析から、それが値0x5000を検索することがわかっています。そのため、イミディエイト オペランドをサポートするようにオペコードを変え、0x3B0D4C904000を値0x81F900500000に変更します。

エミュレーション
このサンプルの環境をセットアップするために、懸念する必要がある唯一の値がEDXです。EDXをエンコードされたペイロードへのポインタにして、ループ中にEAXレジスタに移動させるようにする必要があります。以前と同様に、アドレス空間をセットアップし、アーキテクチャを定義して、いくつかの初期レジスタ値を設定します。

次の結果が得られます。

このバイナリを観察し、文字列をよく見ると、ついにゴールに到達したことがわかります。


プロセスをまとめると次のようになります。
- Microsoft Word文から始まりました
- base64符号化シェルコードを抽出しました
- エンコードされたペイロードを抽出しました
- シェルコードからデコード関数をエミュレートし、ペイロードをデコードしました(バイナリ)
- 新しいバイナリからXOR鍵を抽出しました
- 新しいバイナリから次のエンコードされたペイロードを抽出しました
- 新しいバイナリからデコード関数をエミュレートし、Hancitorをデコードしました(バイナリ)
最後のステップは、すべてをパッケージにし、これを使用してHancitorを含む数千のMicrosoft Word文書をスキャンし、すべてのC2通信を特定することです。これは、作成したHancitorデコーダ スクリプトへのリンクです。
このテストのために、2016年8月15日に初めて見つかり、“WinHost32.exe”という名前のプロセスを作成することをPalo Alto Networks WildFireが観察した、10,000個の一意のMicrosoft Word文書の小さいサンプル セットを取得しました。このことによって、その他いくつかの条件と組み合わせて、Hancitorであると私たちが認識していて、このスクリプトの実行対象にすることができる全テスト サンプルが与えられました。
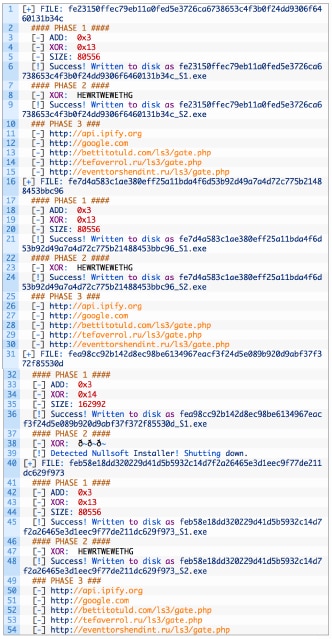
分析
結果はあまり印象的なものではなく、部分的な勝利と部分的な敗北ということになりました。それでもいくつかの興味深い所見が得られました。
サンプル セットでは、デコードに成功した8,851個の全HancitorペイロードにC2 URLが3つしかありませんでした。

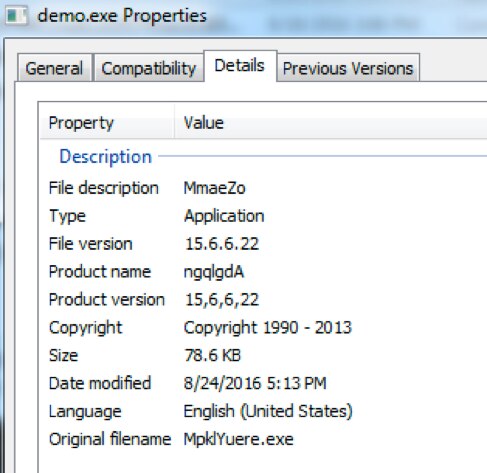
ステージ1ペイロードを見ると、9,967個をデコードしましたが、これはほぼセット全体です。PEファイルのメタデータを確認すると、8,851のファイルが次の特徴を示しました。これらは、この文書の最後のYARAルールに含めています。
CompanyName: ‘SynapticosSoft, Corporation.’
OriginalFilename: ‘MpklYuere.exe’
ProductName: ‘ngqlgdA’
また、3つのXOR鍵がステージ1で使用されているのを特定しました。

データを相関させた後、それぞれの鍵が異なるステージ2ドロッパーに対応し、私たちのスクリプトは最も多く使用されているものを対象にし、デコードするように設計されました。他の2つのデコーダの一般的な観察では、鍵0xEのデコーダは、第2段階のHancitorペイロード“HEWRTWEWETHG”に同じXOR鍵を使用し、単純にデコード スクリプトに追加する可能性が高いです。鍵0x14のその他1,103のファイルはNullsoftインストーラであると特定されました。
ステージ2ペイロードのデコードに成功した8,851個については、ファイル情報を持つPEに気付きませんでしたが、これらすべてに一致するYARAルールが含まれています。ステージ2ファイルについて最後に言及したいことは、ファイル サイズが異なることです。
このデータは、シェルコードの変数から抽出しており、XOR鍵0xEを使用した13ファイルのファイル サイズにわずかな違いがあることがわかります。これはペイロードがわずかに変更されていることを意味するかもしれません。
結論
これが実用的なマルウェア デコーダを構築するための極めて強力なUnicornエンジンを使用する教育デモになったことを望みます。これらの技術は、多くの異なるマルウェア サンプルに適用でき、大量のビット単位のやり取りをプログラムする方法を理解するというやっかいなプロセスからユーザを解放し、分析および対策により注力できます。
インジケーター
次のGitHubリポジトリには、以下にリストする3つのYARAルールがあります。これを使用して、これら2つのブログで説明したさまざまなものを検出できます。また、このブログで構築したスクリプトを検出してHancitorをデコードできます。
hancitor_dropper.yara – Microsoft Word文書のドロッパーを検出します
hancitor_stage1.yara – 最初のPEドロッパーを検出します
hancitor_payload.yara – Hancitorマルウェアのペイロードを検出します
目次
関連項目 マルウェア リソース









 主なサイバー脅威
主なサイバー脅威
